![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
This chapter includes:
In this section, we'll take a look at interrupts, how we deal with them under Neutrino, their impact on scheduling and realtime, and some interrupt-management strategies.
The first thing we need to ask is, “What's an interrupt?”
An interrupt is exactly what it sounds like — an interruption of whatever was going on and a diversion to another task.
For example, suppose you're sitting at your desk working on job “A.” Suddenly, the phone rings. A Very Important Customer (VIC) needs you to immediately answer some skill-testing question. When you've answered the question, you may go back to working on job “A,” or the VIC may have changed your priorities so that you push job “A” off to the side and immediately start on job “B.”
Now let's put that into perspective under Neutrino.
At any moment in time, the processor is busy processing the work for the highest-priority READY thread (this will be a thread that's in the RUNNING state). To cause an interrupt, a piece of hardware on the computer's bus asserts an interrupt line (in our analogy, this was the phone ringing).
As soon as the interrupt line is asserted, the kernel jumps to a piece of code that sets up the environment to run an interrupt service routine (ISR), a piece of software that determines what should happen when that interrupt is detected.
The amount of time that elapses between the time that the interrupt line is asserted by the hardware and the first instruction of the ISR being executed is called the interrupt latency. Interrupt latency is measured in microseconds. Different processors have different interrupt latency times; it's a function of the processor speed, cache architecture, memory speed, and, of course, the efficiency of the operating system.
In our analogy, if you're listening to some music in your headphones and ignoring the ringing phone, it will take you longer to notice this phone “interrupt.” Under Neutrino, the same thing can happen; there's a processor instruction that disables interrupts (cli on the x86, for example). The processor won't notice any interrupts until it reenables interrupts (on the x86, this is the sti opcode).
 |
To avoid CPU-specific assembly language calls, Neutrino provides the following calls: InterruptEnable() and InterruptDisable(), and InterruptLock() and InterruptUnlock(). These take care of all the low-level details on all supported platforms. |
The ISR usually performs the minimum amount of work possible, and then ends (in our analogy, this was the conversation on the telephone with the VIC — we usually don't put the customer on hold and do several hours of work; we just tell the customer, “Okay, I'll get right on that!”). When the ISR ends, it can tell the kernel either that nothing should happen (meaning the ISR has completely handled the event and nothing else needs to be done about it) or that the kernel should perform some action that might cause a thread to become READY.
In our analogy, telling the kernel that the interrupt was handled would be like telling the customer the answer — we can return back to whatever we were doing, knowing that the customer has had their question answered.
Telling the kernel that some action needs to be performed is like telling the customer that you'll get back to them — the telephone has been hung up, but it could ring again.
The ISR is a piece of code that's responsible for clearing the source of the interrupt.
This is a key point, especially in conjunction with this fact: the interrupt runs at a priority higher than any software priority. This means that the amount of time spent in the ISR can have a serious impact on thread scheduling. You should spend as little time as possible in the ISR. Let's examine this in a little more depth.
The hardware device that generated the interrupt will keep the interrupt line asserted until it's sure the software handled the interrupt. Since the hardware can't read minds, the software must tell it when it has responded to the cause of the interrupt. Generally, this is done by reading a status register from a specific hardware port or a block of data from a specific memory location.
In any event, there's usually some form of positive acknowledgment between the hardware and the software to “de-assert” the interrupt line. (Sometimes there isn't an acknowledgment; for example, a piece of hardware may generate an interrupt and assume that the software will handle it.)
Because the interrupt runs at a higher priority than any software thread, we should spend as little time as possible in the ISR itself to minimize the impact on scheduling. If we clear the source of the interrupt simply by reading a register, and perhaps stuffing that value into a global variable, then our job is simple.
This is the kind of processing done by the ISR for the serial port. The serial port hardware generates an interrupt when a character has arrived. The ISR handler reads a status register containing the character, and stuffs that character into a circular buffer. Done. Total processing time: a few microseconds. And, it must be fast. Consider what would happen if you were receiving characters at 115 Kbaud (a character about every 100 µs); if you spent anywhere near 100 µs handling the interrupt, you wouldn't have time to do anything else!
|
Don't let me mislead you though — the serial port's interrupt service routine could take longer to complete. This is because there's a tail-end poll that looks to see if more characters are waiting in the device. |
Clearly, minimizing the amount of time spent in the interrupt can be perceived as “Good customer service” in our analogy — by keeping the amount of time that we're on the phone to a minimum, we avoid giving other customers a busy signal.
What if the handler needs to do a significant amount of work? Here are a couple of possibilities:
In the first case, we'd like to clear the source of the interrupt as fast as possible and then tell the kernel to have a thread do the actual work of talking to the slow hardware. The advantage here is that the ISR spends just a tiny amount of time at the super-high priority, and then the rest of the work is done based on regular thread priorities. This is similar to your answering the phone (the super-high priority), and delegating the real work to one of your assistants. We'll look at how the ISR tells the kernel to schedule someone else later in this chapter.
In the second case, things get ugly. If an ISR doesn't clear the source of the interrupt when it exits, the kernel will immediately be re-interrupted by the Programmable Interrupt Controller (PIC — on the x86, this is the 8259 or equivalent) chip.
|
For PIC fans: we'll talk about edge-sensitive and level-sensitive interrupts shortly. |
We'll continuously be running the ISR, without ever getting a chance to run the thread-level code we need to properly handle the interrupt.
What kind of brain-damaged hardware requires a long time to clear the source of the interrupt? Your basic PC floppy disk controller keeps the interrupt asserted until you've read a number of status register values. Unfortunately, the data in the registers isn't available immediately, and you have to poll for this status data. This could take milliseconds (a long time in computer terms)!
The solution to this is to temporarily mask interrupts — literally tell the PIC to ignore interrupts from this particular source until you tell it otherwise. In this case, even though the interrupt line is asserted from the hardware, the PIC ignores it and doesn't tell the processor about it. This lets your ISR schedule a thread to handle this hardware outside the ISR. When your thread is finished transferring data from the hardware, it can tell the PIC to unmask that interrupt. This lets interrupts from that piece of hardware be recognized again. In our analogy, this is like transferring the VIC's call to your assistant.
How does an ISR tell the kernel that it should now schedule a thread to do some work? (And conversely, how does it tell the kernel that it shouldn't do that?)
Here's some pseudo-code for a typical ISR:
FUNCTION ISR BEGIN
determine source of interrupt
clear source of interrupt
IF thread required to do some work THEN
RETURN (event);
ELSE
RETURN (NULL);
ENDIF
END
The trick is to return an event (of type struct sigevent, which we talked about in the Clocks, Timers, and Getting a Kick Every So Often chapter) instead of NULL. Note that the event that you return must be persistent after the stack frame of the ISR has been destroyed. This means that the event must be declared outside of the ISR, or be passed in from a persistent data area using the area parameter to the ISR, or declared as a static within the ISR itself. Your choice. If you return an event, the kernel delivers it to a thread when your ISR returns. Because the event “alerts” a thread (via a pulse, as we talked about in the Message Passing chapter, or via a signal), this can cause the kernel to reschedule the thread that gets the CPU next. If you return NULL from the ISR, then the kernel knows that nothing special needs to be done at thread time, so it won't reschedule any threads — the thread that was running at the time that the ISR preempted it resumes running.
There's one more piece of the puzzle we've been missing. Most PICs can be programmed to operate in level-sensitive or edge-sensitive mode.
In level-sensitive mode, the interrupt line is deemed to be asserted by the PIC while it's in the “on” state. (This corresponds to label “1” in the diagram below.)
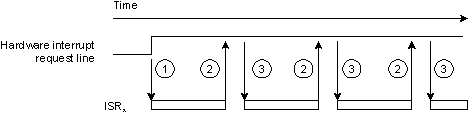
Level-sensitive interrupt assertion.
We can see that this would cause the problem described above with the floppy controller example. Whenever the ISR finishes, the kernel tells the PIC, “Okay, I've handled this interrupt. Tell me the next time that it gets activated” (step 2 in the diagram). In technical terms, the kernel sends an End Of Interrupt (EOI) to the PIC. The PIC looks at the interrupt line and if it's still active would immediately re-interrupt the kernel (step 3).
We could get around this by programming the PIC into edge-sensitive mode. In this mode, the interrupt is noticed by the PIC only on an active-going edge.
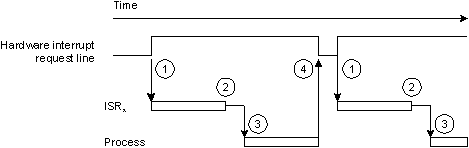
Edge-sensitive interrupt assertion.
Even if the ISR fails to clear the source of the interrupt, when the kernel sends the EOI to the PIC (step 2 in the diagram), the PIC wouldn't re-interrupt the kernel, because there isn't another active-going edge transition after the EOI. In order to recognize another interrupt on that line, the line must first go inactive (step 4), and then active (step 1).
Well, it seems all our problems have been solved! Simply use edge-sensitive for all interrupts.
Unfortunately, edge-sensitive mode has a problem of its own.
Suppose your ISR fails to clear the cause of the interrupt. The hardware would still have the interrupt line asserted when the kernel issues the EOI to the PIC. However, because the PIC is operating in edge-sensitive mode, it never sees another interrupt from that device.
Now what kind of bozo would write an ISR that forgot to clear the source of the interrupt? Unfortunately it isn't that cut-and-dried. Consider a case where two devices (let's say a SCSI bus adapter and an Ethernet card) are sharing the same interrupt line, on a hardware bus architecture that allows that. (Now you're asking, “Who'd set up a machine like that?!?” Well, it happens, especially if the number of interrupt sources on the PIC is in short supply!) In this case, the two ISR routines would be attached to the same interrupt vector (this is legal, by the way), and the kernel would call them in turn whenever it got an interrupt from the PIC for that hardware interrupt level.
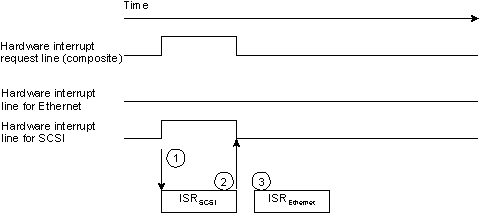
Sharing interrupts — one at a time.
In this case, because only one of the hardware devices was active when its associated ISR ran (the SCSI device), it correctly cleared the source of the interrupt (step 2). Note that the kernel runs the ISR for the Ethernet device (in step 3) regardless — it doesn't know whether the Ethernet hardware requires servicing or not as well, so it always runs the whole chain.
But consider this case:
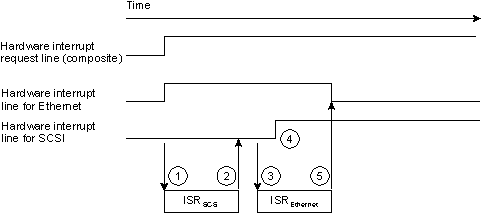
Sharing interrupts — several at once.
Here's where the problem lies.
The Ethernet device interrupted first. This caused the interrupt line to be asserted (active-going edge was noted by the PIC), and the kernel called the first interrupt handler in the chain (the SCSI disk driver; step 1 in the diagram). The SCSI disk driver's ISR looked at its hardware and said, “Nope, wasn't me. Oh well, ignore it” (step 2). Then the kernel called the next ISR in the chain, the Ethernet ISR (step 3). The Ethernet ISR looked at the hardware and said, “Hey! That's my hardware that triggered the interrupt. I'm going to clear it.” Unfortunately, while it was clearing it, the SCSI device generated an interrupt (step 4).
When the Ethernet ISR finished clearing the source of the interrupt (step 5), the interrupt line is still asserted, thanks to the SCSI hardware device. However, the PIC, being programmed in edge-sensitive mode, is looking for an inactive-to-active transition (on the composite line) before recognizing another interrupt. That isn't going to happen because the kernel has already called both interrupt service routines and is now waiting for another interrupt from the PIC.
In this case, a level-sensitive solution would be appropriate because when the Ethernet ISR finishes and the kernel issues the EOI to the PIC, the PIC would pick up the fact that an interrupt is still active on the bus and re-interrupt the kernel. The kernel would then run through the chain of ISRs, and this time the SCSI driver would get a chance to run and clear the source of the interrupt.
The selection of edge-sensitive versus level-sensitive is something that will depend on the hardware and the startup code. Some hardware will support only one or the other; hardware that supports either mode will be programmed by the startup code to one or the other. You'll have to consult the BSP (Board Support Package) documentation that came with your system to get a definitive answer.
Let's see how to set up interrupt handlers — the calls, the characteristics, and some strategies.
To attach to an interrupt source, you'd use either InterruptAttach() or InterruptAttachEvent().
#include <sys/neutrino.h>
int
InterruptAttachEvent (int intr,
const struct sigevent *event,
unsigned flags);
int
InterruptAttach (int intr,
const struct sigevent *
(*handler) (void *area, int id),
const void *area,
int size,
unsigned flags);
The intr argument specifies which interrupt you wish to attach the specified handler to. The values passed are defined by the startup code that initialized the PIC (amongst other things) just before Neutrino was started. (There's more information on the startup code in your Neutrino documentation; look in the Utilities Reference, under startup-*; e.g., startup-p5064.)
At this point, the two functions InterruptAttach() and InterruptAttachEvent() differ. Let's look at InterruptAttachEvent() as it's simpler, first. Then we'll come back to InterruptAttach().
The InterruptAttachEvent() function takes two additional arguments: the argument event, which is a pointer to the struct sigevent that should be delivered, and a flags parameter. InterruptAttachEvent() tells the kernel that the event should be returned whenever the interrupt is detected, and that the interrupt level should be masked off. Note that it's the kernel that interprets the event and figures out which thread should be made READY.
With InterruptAttach(), we're specifying a different set of parameters. The handler parameter is the address of a function to call. As you can see from the prototype, handler() returns a struct sigevent, which indicates what kind of an event to return, and takes two parameters. The first passed parameter is the area, which is simply the area parameter that's passed to InterruptAttach() to begin with. The second parameter, id, is the identification of the interrupt, which is also the return value from InterruptAttach(). This is used to identify the interrupt and to mask, unmask, lock, or unlock the interrupt. The fourth parameter to InterruptAttach() is the size, which indicates how big (in bytes) the data area that you passed in area is. Finally, the flags parameter is the same as that passed for the InterruptAttachEvent(); we'll discuss that shortly.
At this point, you've called either InterruptAttachEvent() or InterruptAttach().
|
Since attaching an interrupt isn't something you want everyone to be able to do, Neutrino allows only threads that have “I/O privileges” enabled to do it (see the ThreadCtl() function in the Neutrino Library Reference). Only threads running from the root account or that are setuid() to root can obtain “I/O privileges”; hence we're effectively limiting this ability to root. |
Here's a code snippet that attaches an ISR to the hardware interrupt vector, which we've identified in our code sample by the constant HW_SERIAL_IRQ:
#include <sys/neutrino.h>
int interruptID;
const struct sigevent *
intHandler (void *arg, int id)
{
...
}
int
main (int argc, char **argv)
{
...
interruptID = InterruptAttach (HW_SERIAL_IRQ,
intHandler,
&event,
sizeof (event),
0);
if (interruptID == -1) {
fprintf (stderr, "%s: can't attach to IRQ %d\n",
progname, HW_SERIAL_IRQ);
perror (NULL);
exit (EXIT_FAILURE);
}
...
return (EXIT_SUCCESS);
}
This creates the association between the ISR (the routine called intHandler(); see below for details) and the hardware interrupt vector HW_SERIAL_IRQ.
At this point, if an interrupt occurs on that interrupt vector, our ISR will be dispatched. When we call InterruptAttach(), the kernel unmasks the interrupt source at the PIC level (unless it's already unmasked, which would be the case if multiple ISRs were sharing the same interrupt).
When done with the ISR, we may wish to break the association between the ISR and the interrupt vector:
int InterruptDetach (int id);
I said “may” because threads that handle interrupts are generally found in servers, and servers generally hang around forever. It's therefore conceivable that a well-constructed server wouldn't ever issue the InterruptDetach() function call. Also, the OS will remove any interrupt handlers that a thread or process may have associated with it when the thread or process dies. So, simply falling off the end of main(), calling exit(), or exiting due to a SIGSEGV, will dissociate your ISR from the interrupt vector, automagically. (Of course, you'll probably want to handle this a little better, and stop your device from generating interrupts. If another device is sharing the interrupt, then there are no two ways about it — you must clean up, otherwise you won't get any more interrupts if running edge-sensitive mode, or you'll get a constant flood of ISR dispatches if running in level-sensitive mode.)
Continuing the above example, if we want to detach, we'd use the following code:
void
terminateInterrupts (void)
{
InterruptDetach (interruptID);
}
If this was the last ISR associated with that interrupt vector, the kernel would automatically mask the interrupt source at the PIC level so that it doesn't generate interrupts.
The last parameter, flags, controls all kinds of things:
Let's look at the ISR itself. In the first example, we'll look at using the InterruptAttach() function. Then, we'll see the exact same thing, except with InterruptAttachEvent().
Continuing our example, here's the ISR intHandler(). It looks at the 8250 serial port chip that we assume is attached to HW_SERIAL_IRQ:
/*
* int1.c
*/
#include <stdio.h>
#include <sys/neutrino.h>
#define REG_RX 0
#define REG_II 2
#define REG_LS 5
#define REG_MS 6
#define IIR_MASK 0x07
#define IIR_MSR 0x00
#define IIR_THE 0x02
#define IIR_RX 0x04
#define IIR_LSR 0x06
#define IIR_MASK 0x07
volatile int serial_msr; // saved contents of Modem Status Reg
volatile int serial_rx; // saved contents of RX register
volatile int serial_lsr; // saved contents of Line Status Reg
static int base_reg = 0x2f8;
const struct sigevent *
intHandler (void *arg, int id)
{
int iir;
struct sigevent *event = (struct sigevent *)arg;
/*
* determine the source of the interrupt
* by reading the Interrupt Identification Register
*/
iir = in8 (base_reg + REG_II) & IIR_MASK;
/* no interrupt? */
if (iir & 1) {
/* then no event */
return (NULL);
}
/*
* figure out which interrupt source caused the interrupt,
* and determine if a thread needs to do something about it.
* (The constants are based on the 8250 serial port's interrupt
* identification register.)
*/
switch (iir) {
case IIR_MSR:
serial_msr = in8 (base_reg + REG_MS);
/* wake up thread */
return (event);
break;
case IIR_THE:
/* do nothing */
break;
case IIR_RX:
/* note the character */
serial_rx = in8 (base_reg + REG_RX);
break;
case IIR_LSR:
/* note the line status reg. */
serial_lsr = in8 (base_reg + REG_LS);
break;
default:
break;
}
/* don't bother anyone */
return (NULL);
}
The first thing we notice is that any variable that the ISR touches must be declared volatile. On a single-processor box, this isn't for the ISR's benefit, but rather for the benefit of the thread-level code, which can be interrupted at any point by the ISR. Of course, on an SMP box, we could have the ISR running concurrently with the thread-level code, in which case we have to be very careful about these sorts of things.
With the volatile keyword, we're telling the compiler not to cache the value of any of these variables, because they can change at any point during execution.
The next thing we notice is the prototype for the interrupt service routine itself. It's marked as const struct sigevent *. This says that the routine intHandler() returns a struct sigevent pointer. This is standard for all interrupt service routines.
Finally, notice that the ISR decides if the thread will or won't be sent an event. Only in the case of a Modem Status Register (MSR) interrupt do we want the event to be delivered (the event is identified by the variable event, which was conveniently passed to the ISR when we attached it). In all other cases, we ignore the interrupt (and update some global variables). In all cases, however, we clear the source of the interrupt. This is done by reading the I/O port via in8().
If we were to recode the example above to use InterruptAttachEvent(), it would look like this:
/*
* part of int2.c
*/
#include <stdio.h>
#include <sys/neutrino.h>
#define HW_SERIAL_IRQ 3
#define REG_RX 0
#define REG_II 2
#define REG_LS 5
#define REG_MS 6
#define IIR_MASK 0x07
#define IIR_MSR 0x00
#define IIR_THE 0x02
#define IIR_RX 0x04
#define IIR_LSR 0x06
#define IIR_MASK 0x07
static int base_reg = 0x2f8;
int
main (int argc, char **argv)
{
int intId; // interrupt id
int iir; // interrupt identification register
int serial_msr; // saved contents of Modem Status Reg
int serial_rx; // saved contents of RX register
int serial_lsr; // saved contents of Line Status Reg
struct sigevent event;
// usual main() setup stuff...
// set up the event
intId = InterruptAttachEvent (HW_SERIAL_IRQ, &event, 0);
for (;;) {
// wait for an interrupt event (could use MsgReceive instead)
InterruptWait (0, NULL);
/*
* determine the source of the interrupt (and clear it)
* by reading the Interrupt Identification Register
*/
iir = in8 (base_reg + REG_II) & IIR_MASK;
// unmask the interrupt, so we can get the next event
InterruptUnmask (HW_SERIAL_IRQ, intId);
/* no interrupt? */
if (iir & 1) {
/* then wait again for next */
continue;
}
/*
* figure out which interrupt source caused the interrupt,
* and determine if we need to do something about it
*/
switch (iir) {
case IIR_MSR:
serial_msr = in8 (base_reg + REG_MS);
/*
* perform whatever processing you would've done in
* the other example...
*/
break;
case IIR_THE:
/* do nothing */
break;
case IIR_RX:
/* note the character */
serial_rx = in8 (base_reg + REG_RX);
break;
case IIR_LSR:
/* note the line status reg. */
serial_lsr = in8 (base_reg + REG_LS);
break;
}
}
/* You won't get here. */
return (0);
}
Notice that the InterruptAttachEvent() function returns an interrupt identifier (a small integer). We've saved this into the variable intId so that we can use it later when we go to unmask the interrupt.
After we've attached the interrupt, we then need to wait for the interrupt to hit. Since we're using InterruptAttachEvent(), we'll get the event that we created earlier dropped on us for every interrupt. Contrast this with what happened when we used InterruptAttach() — in that case, our ISR determined whether or not to drop an event on us. With InterruptAttachEvent(), the kernel has no idea whether or not the hardware event that caused the interrupt was “significant” for us, so it drops the event on us every time it occurs, masks the interrupt, and lets us decide if the interrupt was significant or not.
We handled the decision in the code example for InterruptAttach() (above) by returning either a struct sigevent to indicate that something should happen, or by returning the constant NULL. Notice the changes that we did to our code when we modified it for InterruptAttachEvent():
Where you decide to clear the source of the interrupt depends on your hardware and the notification scheme you've chosen. With the combination of SIGEV_INTR and InterruptWait(), the kernel doesn't “queue” more than one notification; with SIGEV_PULSE and MsgReceive(), the kernel will queue all the notifications. If you're using signals (and SIGEV_SIGNAL, for example), you define whether the signals are queued or not. With some hardware schemes, you may need to clear the source of the interrupt before you can read more data out of the device; with other pieces of hardware, you don't have to and can read data while the interrupt is asserted.
|
An ISR returning SIGEV_THREAD is one scenario that fills me with absolute fear! I'd recommend avoiding this “feature” if at all possible. |
In the serial port example above, we've decided to use InterruptWait(), which will queue one entry. The serial port hardware may assert another interrupt immediately after we've read the interrupt identification register, but that's fine, because at most one SIGEV_INTR will get queued. We'll pick up this notification on our next iteration of the for loop.
This naturally brings us to the question, “Why would I use one over the other?”
The most obvious advantage of InterruptAttachEvent() is that it's simpler to use than InterruptAttach() — there's no ISR routine (hence no need to debug it). Another advantage is that since there's nothing running in kernel space (as an ISR routine would be) there's no danger of crashing the entire system. If you do encounter a programming error, then the process will crash, rather than the whole system. However, it may be more or less efficient than InterruptAttach() depending on what you're trying to achieve. This issue is complex enough that reducing it to a few words (like “faster” or “better”) probably won't suffice. We'll need to look at a few pictures and scenarios.
Here's what happens when we use InterruptAttach():
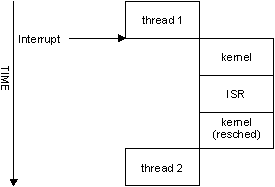
Control flow with InterruptAttach().
The thread that's currently running (“thread1”) gets interrupted, and we go into the kernel. The kernel saves the context of “thread1.” The kernel then does a lookup to see who's responsible for handling the interrupt and decides that “ISR1” is responsible. At this point, the kernel sets up the context for “ISR1” and transfers control. “ISR1” looks at the hardware and decides to return a struct sigevent. The kernel notices the return value, figures out who needs to handle it, and makes them READY. This may cause the kernel to schedule a different thread to run, “thread2.”
Now, let's contrast that with what happens when we use InterruptAttachEvent():
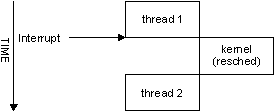
Control flow with InterruptAttachEvent().
In this case, the servicing path is much shorter. We made one context switch from the currently running thread (“thread1”) into the kernel. Instead of doing another context switch into the ISR, the kernel simply “pretended” that the ISR returned a struct sigevent and acted on it, rescheduling “thread2” to run.
Now you're thinking, “Great! I'm going to forget all about InterruptAttach() and just use the easier InterruptAttachEvent().”
That's not such a great idea, because you may not need to wake up for every interrupt that the hardware generates! Go back and look at the source example above — it returned an event only when the modem status register on the serial port changed state, not when a character arrived, not when a line status register changed, and not when the transmit holding buffer was empty.
In that case, especially if the serial port was receiving characters (that you wanted to ignore), you'd be wasting a lot of time rescheduling your thread to run, only to have it look at the serial port and decide that it didn't want to do anything about it anyway. In that case, things would look like this:
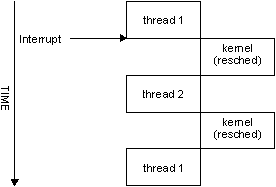
Control flow with InterruptAttachEvent() and unnecessary rescheduling.
All that happens is that you incur a thread-to-thread context switch to get into “thread2” which looks at the hardware and decides that it doesn't need to do anything about it, costing you another thread-to-thread context switch to get back to “thread1.”
Here's how things would look if you used InterruptAttach() but didn't want to schedule a different thread (i.e., you returned):
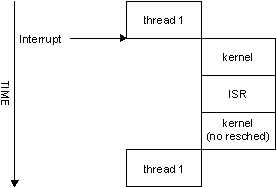
Control flow with InterruptAttach() with no thread rescheduling.
The kernel knows that “thread1” was running, and the ISR didn't tell it to do anything, so it can just go right ahead and let “thread1” continue after the interrupt.
Just for reference, here's what the InterruptAttachEvent() function call does (note that this isn't the real source, because InterruptAttachEvent() actually binds a data structure to the kernel — it isn't implemented as a discrete function that gets called!):
// the "internal" handler
static const struct sigevent *
internalHandler (void *arg, int id)
{
struct sigevent *event = arg;
InterruptMask (intr, id);
return (arg);
}
int
InterruptAttachEvent (int intr,
const struct sigevent *event, unsigned flags)
{
static struct sigevent static_event;
memcpy (&static_event, event, sizeof (static_event));
return (InterruptAttach (intr, internalHandler,
&static_event, sizeof (*event), flags));
}
So, which function should you use? For low-frequency interrupts, you can almost always get away with InterruptAttachEvent(). Since the interrupts occur infrequently, there won't be a significant impact on overall system performance, even if you do schedule threads unnecessarily. The only time that this can come back to haunt you is if another device is chained off the same interrupt — in this case, because InterruptAttachEvent() masks the source of the interrupt, it'll effectively disable interrupts from the other device until the interrupt source is unmasked. This is a concern only if the first device takes a long time to be serviced. In the bigger picture, this is a hardware system design issue — you shouldn't chain slow-to-respond devices on the same line as high-speed devices.
For higher-frequency interrupts, it's a toss up, and there are many factors:
The next issue we should tackle is the list of functions an ISR is allowed to call.
Let me digress just a little at this point. Historically, the reason that ISRs were so difficult to write (and still are in most other operating systems) is that the ISR runs in a special environment.
One particular thing that complicates writing ISRs is that the ISR isn't actually a “proper” thread as far as the kernel is concerned. It's this weird “hardware” thread, if you want to call it that. This means that the ISR isn't allowed to do any “thread-level” things, like messaging, synchronization, kernel calls, disk I/O, etc.
But doesn't that make it much harder to write ISR routines? Yes it does. The solution, therefore, is to do as little work as possible in the ISR, and do the rest of the work at thread-level, where you have access to all the services.
Your goals in the ISR should be:
This “architecture” hinges on the fact that Neutrino has very fast context-switch times. You know that you can get into your ISR quickly to do the time-critical work. You also know that when the ISR returns an event to trigger thread-level work, that thread will start quickly as well. It's this “don't do anything in the ISR” philosophy that makes Neutrino ISRs so simple!
So, what calls can you use in the ISR? Here's a summary (for the official list, see the Summary of Safety Information appendix in the Neutrino Library Reference):
Basically, the rule of thumb is, “Don't use anything that's going to take a huge amount of stack space or time, and don't use anything that issues kernel calls.” The stack space requirement stems from the fact that ISRs have very limited stacks.
The list of interrupt-safe functions makes sense — you might want to move some memory around, in which case the mem*() and str*() functions are a good choice. You'll most likely want to read data registers from the hardware (in order to save transitory data variables and/or clear the source of the interrupt), so you'll want to use the in*() and out*() functions.
What about the bewildering choice of Interrupt*() functions? Let's examine them in pairs:
Keep in mind that InterruptMask() and InterruptUnmask() are counting — you must “unmask” the same number of times that you've “masked” in order for the interrupt source to be able to interrupt you again.
By the way, note that the InterruptAttachEvent() performs the InterruptMask() for you (in the kernel) — therefore you must call InterruptUnmask() from your interrupt-handling thread.
The one thing that bears repeating is that on an SMP system, it is possible to have both the interrupt service routine and another thread running at the same time.
Keep the following things in mind when dealing with interrupts:
|
|
|
|