![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
Interprocess Communication plays a fundamental role in the transformation of QNX Neutrino from an embedded realtime kernel into a full-scale POSIX operating system. As various service-providing processes are added to the microkernel, IPC is the “glue” that connects those components into a cohesive whole.
Although message passing is the primary form of IPC in QNX Neutrino, several other forms are available as well. Unless otherwise noted, those other forms of IPC are built over our native message passing. The strategy is to create a simple, robust IPC service that can be tuned for performance through a simplified code path in the microkernel; more “feature cluttered” IPC services can then be implemented from these.
Benchmarks comparing higher-level IPC services (like pipes and FIFOs implemented over our messaging) with their monolithic kernel counterparts show comparable performance.
QNX Neutrino offers at least the following forms of IPC:
| Service: | Implemented in: |
|---|---|
| Message-passing | Kernel |
| Signals | Kernel |
| POSIX message queues | External process |
| Shared memory | Process manager |
| Pipes | External process |
| FIFOs | External process |
The designer can select these services on the basis of bandwidth requirements, the need for queuing, network transparency, etc. The trade-off can be complex, but the flexibility is useful.
As part of the engineering effort that went into defining the QNX Neutrino microkernel, the focus on message passing as the fundamental IPC primitive was deliberate. As a form of IPC, message passing (as implemented in MsgSend(), MsgReceive(), and MsgReply()), is synchronous and copies data. Let's explore these two attributes in more detail.
A thread that does a MsgSend() to another thread (which could be within another process) will be blocked until the target thread does a MsgReceive(), processes the message, and executes a MsgReply(). If a thread executes a MsgReceive() without a previously sent message pending, it will block until another thread executes a MsgSend().
In Neutrino, a server thread typically loops, waiting to receive a message from a client thread. As described earlier, a thread — whether a server or a client — is in the READY state if it can use the CPU. It might not actually be getting any CPU time because of its and other threads' priority and scheduling algorithm, but the thread isn't blocked.
Let's look first at the client thread:
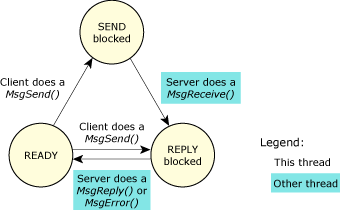
Changes of state for a client thread in a send-receive-reply transaction.
Next, let's consider the server thread:
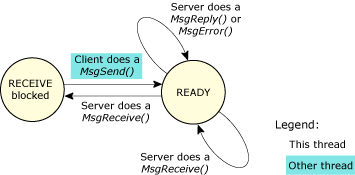
Changes of state for a server thread in a send-receive-reply transaction.
This inherent blocking synchronizes the execution of the sending thread, since the act of requesting that the data be sent also causes the sending thread to be blocked and the receiving thread to be scheduled for execution. This happens without requiring explicit work by the kernel to determine which thread to run next (as would be the case with most other forms of IPC). Execution and data move directly from one context to another.
Data-queuing capabilities are omitted from these messaging primitives because queueing could be implemented when needed within the receiving thread. The sending thread is often prepared to wait for a response; queueing is unnecessary overhead and complexity (i.e. it slows down the nonqueued case). As a result, the sending thread doesn't need to make a separate, explicit blocking call to wait for a response (as it would if some other IPC form had been used).
While the send and receive operations are blocking and synchronous, MsgReply() (or MsgError()) doesn't block. Since the client thread is already blocked waiting for the reply, no additional synchronization is required, so a blocking MsgReply() isn't needed. This allows a server to reply to a client and continue processing while the kernel and/or networking code asynchronously passes the reply data to the sending thread and marks it ready for execution. Since most servers will tend to do some processing to prepare to receive the next request (at which point they block again), this works out well.
 |
Note that in a network, a reply may not complete as “immediately” as in a local message pass. For more information on network message passing, see the chapter on Qnet networking in this book. |
The MsgReply() function is used to return a status and zero or more bytes to the client. MsgError(), on the other hand, is used to return only a status to the client. Both functions will unblock the client from its MsgSend().
Since our messaging services copy a message directly from the address space of one thread to another without intermediate buffering, the message-delivery performance approaches the memory bandwidth of the underlying hardware. The kernel attaches no special meaning to the content of a message — the data in a message has meaning only as mutually defined by sender and receiver. However, “well-defined” message types are also provided so that user-written processes or threads can augment or substitute for system-supplied services.
The messaging primitives support multipart transfers, so that a message delivered from the address space of one thread to another needn't pre-exist in a single, contiguous buffer. Instead, both the sending and receiving threads can specify a vector table that indicates where the sending and receiving message fragments reside in memory. Note that the size of the various parts can be different for the sender and receiver.
Multipart transfers allow messages that have a header block separate from the data block to be sent without performance-consuming copying of the data to create a contiguous message. In addition, if the underlying data structure is a ring buffer, specifying a three-part message will allow a header and two disjoint ranges within the ring buffer to be sent as a single atomic message. A hardware equivalent of this concept would be that of a scatter/gather DMA facility.
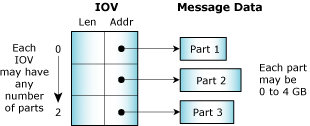
A multipart transfer.
The multipart transfers are also used extensively by filesystems. On a read, the data is copied directly from the filesystem cache into the application using a message with n parts for the data. Each part points into the cache and compensates for the fact that cache blocks aren't contiguous in memory with a read starting or ending within a block.
For example, with a cache block size of 512 bytes, a read of 1454 bytes can be satisfied with a 5-part message:
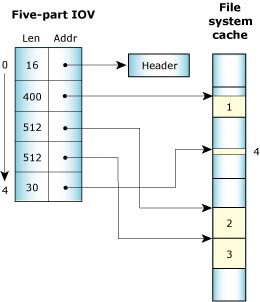
Scatter/gather of a read of 1454 bytes.
Since message data is explicitly copied between address spaces (rather than by doing page table manipulations), messages can be easily allocated on the stack instead of from a special pool of page-aligned memory for MMU “page flipping.” As a result, many of the library routines that implement the API between client and server processes can be trivially expressed, without elaborate IPC-specific memory allocation calls.
For example, the code used by a client thread to request that the filesystem manager execute lseek on its behalf is implemented as follows:
#include <unistd.h>
#include <errno.h>
#include <sys/iomsg.h>
off64_t lseek64(int fd, off64_t offset, int whence) {
io_lseek_t msg;
off64_t off;
msg.i.type = _IO_LSEEK;
msg.i.combine_len = sizeof msg.i;
msg.i.offset = offset;
msg.i.whence = whence;
msg.i.zero = 0;
if(MsgSend(fd, &msg.i, sizeof msg.i, &off, sizeof off) == -1) {
return -1;
}
return off;
}
off64_t tell64(int fd) {
return lseek64(fd, 0, SEEK_CUR);
}
off_t lseek(int fd, off_t offset, int whence) {
return lseek64(fd, offset, whence);
}
off_t tell(int fd) {
return lseek64(fd, 0, SEEK_CUR);
}
This code essentially builds a message structure on the stack, populates it with various constants and passed parameters from the calling thread, and sends it to the filesystem manager associated with fd. The reply indicates the success or failure of the operation.
|
This implementation doesn't prevent the kernel from detecting large message transfers and choosing to implement “page flipping” for those cases. Since most messages passed are quite tiny, copying messages is often faster than manipulating MMU page tables. For bulk data transfer, shared memory between processes (with message-passing or the other synchronization primitives for notification) is also a viable option. |
For simple single-part messages, the OS provides functions that take a pointer directly to a buffer without the need for an IOV (input/output vector). In this case, the number of parts is replaced by the size of the message directly pointed to. In the case of the message send primitive — which takes a send and a reply buffer — this introduces four variations:
| Function | Send message | Reply message |
|---|---|---|
| MsgSend() | Simple | Simple |
| MsgSendsv() | Simple | IOV |
| MsgSendvs() | IOV | Simple |
| MsgSendv() | IOV | IOV |
The other messaging primitives that take a direct message simply drop the trailing “v” in their names:
| IOV | Simple direct |
|---|---|
| MsgReceivev() | MsgReceive() |
| MsgReceivePulsev() | MsgReceivePulse() |
| MsgReplyv() | MsgReply() |
| MsgReadv() | MsgRead() |
| MsgWritev() | MsgWrite() |
In QNX Neutrino, message passing is directed towards channels and connections, rather than targeted directly from thread to thread. A thread that wishes to receive messages first creates a channel; another thread that wishes to send a message to that thread must first make a connection by “attaching” to that channel.
Channels are required by the message kernel calls and are used by servers to MsgReceive() messages on. Connections are created by client threads to “connect” to the channels made available by servers. Once connections are established, clients can MsgSend() messages over them. If a number of threads in a process all attach to the same channel, then the connections all map to the same kernel object for efficiency. Channels and connections are named within a process by a small integer identifier. Client connections map directly into file descriptors.
Architecturally, this is a key point. By having client connections map directly into FDs, we have eliminated yet another layer of translation. We don't need to “figure out” where to send a message based on the file descriptor (e.g. via a read(fd) call). Instead, we can simply send a message directly to the “file descriptor” (i.e. connection ID).
| Function | Description |
|---|---|
| ChannelCreate() | Create a channel to receive messages on. |
| ChannelDestroy() | Destroy a channel. |
| ConnectAttach() | Create a connection to send messages on. |
| ConnectDetach() | Detach a connection. |
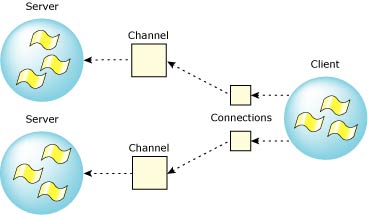
Connections map elegantly into file descriptors.
A process acting as a server would implement an event loop to receive and process messages as follows:
chid = ChannelCreate(flags);
SETIOV(&iov, &msg, sizeof(msg));
for(;;) {
rcv_id = MsgReceivev( chid, &iov, parts, &info );
switch( msg.type ) {
/* Perform message processing here */
}
MsgReplyv( rcv_id, &iov, rparts );
}
This loop allows the thread to receive messages from any thread that had a connection to the channel.
|
The server can also use name_attach() to create a channel and associate a name with it. The sender process can then use name_open() to locate that name and create a connection to it. |
The channel has several lists of messages associated with it:
While in any of these lists, the waiting thread is blocked (i.e. RECEIVE-, SEND-, or REPLY-blocked). Multiple threads and multiple clients may wait on one channel.
In addition to the synchronous Send/Receive/Reply services, the OS also supports fixed-size, nonblocking messages. These are referred to as pulses and carry a small payload (four bytes of data plus a single byte code).
Pulses pack a relatively small payload — eight bits of code and 32 bits of data. Pulses are often used as a notification mechanism within interrupt handlers. They also allow servers to signal clients without blocking on them.
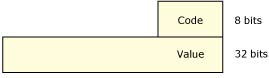
Pulses pack a small payload.
A server process receives messages and pulses in priority order. As the threads within the server receive requests, they then inherit the priority (but not the scheduling algorithm) of the sending thread. As a result, the relative priorities of the threads requesting work of the server are preserved, and the server work will be executed at the appropriate priority. This message-driven priority inheritance avoids priority-inversion problems.
For example, suppose the system includes the following:
Without priority inheritance, if T2 sends a message to the server, it's effectively getting work done for it at priority 22, so T2's priority has been inverted.
What actually happens is that when the server receives a message, its effective priority changes to that of the highest-priority sender. In this case, T2's priority is lower than the server's, so the change in the server's effective priority takes place when the server receives the message.
Next, suppose that T1 sends a message to the server while it's still at priority 10. Since T1's priority is higher than the server's current priority, the change in the server's priority happens when T1 sends the message.
The change happens before the server receives the message to avoid another case of priority inversion. If the server's priority remains unchanged at 10, and another thread, T3, starts to run at priority 11, the server has to wait until T3 lets it have some CPU time so that it can eventually receive T1's message. So, T1 would would be delayed by a lower-priority thread, T3.
You can turn off priority inheritance by specifying the _NTO_CHF_FIXED_PRIORITY flag when you call ChannelCreate(). If you're using adaptive partitioning, this flag also causes the receiving threads not to run in the sending threads' partitions.
The message-passing API consists of the following functions:
| Function | Description |
|---|---|
| MsgSend() | Send a message and block until reply. |
| MsgReceive() | Wait for a message. |
| MsgReceivePulse() | Wait for a tiny, nonblocking message (pulse). |
| MsgReply() | Reply to a message. |
| MsgError() | Reply only with an error status. No message bytes are transferred. |
| MsgRead() | Read additional data from a received message. |
| MsgWrite() | Write additional data to a reply message. |
| MsgInfo() | Obtain info on a received message. |
| MsgSendPulse() | Send a tiny, nonblocking message (pulse). |
| MsgDeliverEvent() | Deliver an event to a client. |
| MsgKeyData() | Key a message to allow security checks. |
For information about messages from the programming point of view, see the Message Passing chapter of Getting Started with QNX Neutrino.
Architecting a QNX Neutrino application as a team of cooperating threads and processes via Send/Receive/Reply results in a system that uses synchronous notification. IPC thus occurs at specified transitions within the system, rather than asynchronously.
A significant problem with asynchronous systems is that event notification requires signal handlers to be run. Asynchronous IPC can make it difficult to thoroughly test the operation of the system and make sure that no matter when the signal handler runs, that processing will continue as intended. Applications often try to avoid this scenario by relying on a “window” explicitly opened and shut, during which signals will be tolerated.
With a synchronous, nonqueued system architecture built around Send/Receive/Reply, robust application architectures can be very readily implemented and delivered.
Avoiding deadlock situations is another difficult problem when constructing applications from various combinations of queued IPC, shared memory, and miscellaneous synchronization primitives. For example, suppose thread A doesn't release mutex 1 until thread B releases mutex 2. Unfortunately, if thread B is in the state of not releasing mutex 2 until thread A releases mutex 1, a standoff results. Simulation tools are often invoked in order to ensure that deadlock won't occur as the system runs.
The Send/Receive/Reply IPC primitives allow the construction of deadlock-free systems with the observation of only these simple rules:
The first rule is an obvious avoidance of the standoff situation, but the second rule requires further explanation. The team of cooperating threads and processes is arranged as follows:
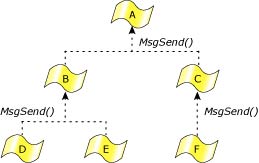
Threads should always send up to higher-level threads.
Here the threads at any given level in the hierarchy never send to each other, but send only upwards instead.
One example of this might be a client application that sends to a database server process, which in turn sends to a filesystem process. Since the sending threads block and wait for the target thread to reply, and since the target thread isn't send-blocked on the sending thread, deadlock can't happen.
But how does a higher-level thread notify a lower-level thread that it has the results of a previously requested operation? (Assume the lower-level thread didn't want to wait for the replied results when it last sent.)
QNX Neutrino provides a very flexible architecture with the MsgDeliverEvent() kernel call to deliver nonblocking events. All of the common asynchronous services can be implemented with this. For example, the server-side of the select() call is an API that an application can use to allow a thread to wait for an I/O event to complete on a set of file descriptors. In addition to an asynchronous notification mechanism being needed as a “back channel” for notifications from higher-level threads to lower-level threads, we can also build a reliable notification system for timers, hardware interrupts, and other event sources around this.
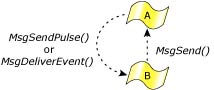
A higher-level thread can “send” a pulse event.
A related issue is the problem of how a higher-level thread can request work of a lower-level thread without sending to it, risking deadlock. The lower-level thread is present only to serve as a “worker thread” for the higher-level thread, doing work on request. The lower-level thread would send in order to “report for work,” but the higher-level thread wouldn't reply then. It would defer the reply until the higher-level thread had work to be done, and it would reply (which is a nonblocking operation) with the data describing the work. In effect, the reply is being used to initiate work, not the send, which neatly side-steps rule #1.
A significant advance in the kernel design for QNX Neutrino is the event-handling subsystem. POSIX and its realtime extensions define a number of asynchronous notification methods (e.g. UNIX signals that don't queue or pass data, POSIX realtime signals that may queue and pass data, etc.).
The kernel also defines additional, QNX-specific notification techniques such as pulses. Implementing all of these event mechanisms could have consumed significant code space, so our implementation strategy was to build all of these notification methods over a single, rich, event subsystem.
A benefit of this approach is that capabilities exclusive to one notification technique can become available to others. For example, an application can apply the same queueing services of POSIX realtime signals to UNIX signals. This can simplify the robust implementation of signal handlers within applications.
The events encountered by an executing thread can come from any of three sources:
The event itself can be any of a number of different types: QNX Neutrino pulses, interrupts, various forms of signals, and forced “unblock” events. “Unblock” is a means by which a thread can be released from a deliberately blocked state without any explicit event actually being delivered.
Given this multiplicity of event types, and applications needing the ability to request whichever asynchronous notification technique best suits their needs, it would be awkward to require that server processes (the higher-level threads from the previous section) carry code to support all these options.
Instead, the client thread can give a data structure, or “cookie,” to the server to hang on to until later. When the server needs to notify the client thread, it will invoke MsgDeliverEvent() and the microkernel will set the event type encoded within the cookie upon the client thread.
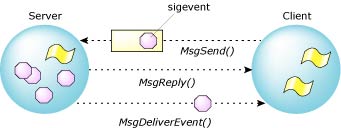
The client sends a sigevent to the server.
The ionotify() function is a means by which a client thread can request asynchronous event delivery. Many of the POSIX asynchronous services (e.g. mq_notify() and the client-side of the select()) are built on top of it. When performing I/O on a file descriptor (fd), the thread may choose to wait for an I/O event to complete (for the write() case), or for data to arrive (for the read() case). Rather than have the thread block on the resource manager process that's servicing the read/write request, ionotify() can allow the client thread to post an event to the resource manager that the client thread would like to receive when the indicated I/O condition occurs. Waiting in this manner allows the thread to continue executing and responding to event sources other than just the single I/O request.
The select() call is implemented using I/O notification and allows a thread to block and wait for a mix of I/O events on multiple fd's while continuing to respond to other forms of IPC.
Here are the conditions upon which the requested event can be delivered:
The OS supports the 32 standard POSIX signals (as in UNIX) as well as the POSIX realtime signals, both numbered from a kernel-implemented set of 64 signals with uniform functionality. While the POSIX standard defines realtime signals as differing from UNIX-style signals (in that they may contain four bytes of data and a byte code and may be queued for delivery), this functionality can be explicitly selected or deselected on a per-signal basis, allowing this converged implementation to still comply with the standard.
Incidentally, the UNIX-style signals can select POSIX realtime signal queuing, if the application wants it. QNX Neutrino also extends the signal-delivery mechanisms of POSIX by allowing signals to be targeted at specific threads, rather than simply at the process containing the threads. Since signals are an asynchronous event, they're also implemented with the event-delivery mechanisms.
| Microkernel call | POSIX call | Description |
|---|---|---|
| SignalKill() | kill(), pthread_kill(), raise(), sigqueue() | Set a signal on a process group, process, or thread. |
| SignalAction() | sigaction() | Define action to take on receipt of a signal. |
| SignalProcmask() | sigprocmask(), pthread_sigmask() | Change signal blocked mask of a thread. |
| SignalSuspend() | sigsuspend(), pause() | Block until a signal invokes a signal handler. |
| SignalWaitinfo() | sigwaitinfo() | Wait for signal and return info on it. |
The original POSIX specification defined signal operation on processes only. In a multithreaded process, the following rules are followed:
When a signal is targeted at a process with a large number of threads, the thread table must be scanned, looking for a thread with the signal unblocked. Standard practice for most multithreaded processes is to mask the signal in all threads but one, which is dedicated to handling them. To increase the efficiency of process-signal delivery, the kernel will cache the last thread that accepted a signal and will always attempt to deliver the signal to it first.
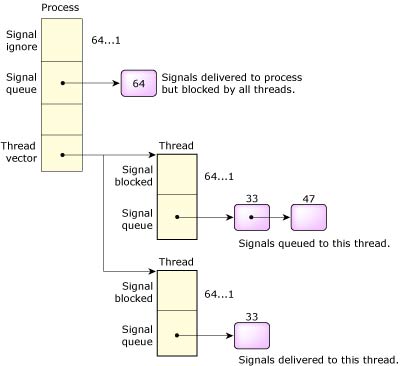
Signal delivery.
The POSIX standard includes the concept of queued realtime signals. QNX Neutrino supports optional queuing of any signal, not just realtime signals. The queuing can be specified on a signal-by-signal basis within a process. Each signal can have an associated 8-bit code and a 32-bit value.
This is very similar to message pulses described earlier. The kernel takes advantage of this similarity and uses common code for managing both signals and pulses. The signal number is mapped to a pulse priority using _SIGMAX – signo. As a result, signals are delivered in priority order with lower signal numbers having higher priority. This conforms with the POSIX standard, which states that existing signals have priority over the new realtime signals.
As mentioned earlier, the OS defines a total of 64 signals. Their range is as follows:
| Signal range | Description |
|---|---|
| 1 ... 57 | 57 POSIX signals (including traditional UNIX signals) |
| 41 ... 56 | 16 POSIX realtime signals (SIGRTMIN to SIGRTMAX) |
| 57 ... 64 | Eight special-purpose QNX Neutrino signals |
The eight special signals cannot be ignored or caught. An attempt to call the signal() or sigaction() functions or the SignalAction() kernel call to change them will fail with an error of EINVAL.
In addition, these signals are always blocked and have signal queuing enabled. An attempt to unblock these signals via the sigprocmask() function or SignalProcmask() kernel call will be quietly ignored.
A regular signal can be programmed to this behavior using the following standard signal calls. The special signals save the programmer from writing this code and protect the signal from accidental changes to this behavior.
sigset_t *set; struct sigaction action; sigemptyset(&set); sigaddset(&set, signo); sigprocmask(SIG_BLOCK, &set, NULL); action.sa_handler = SIG_DFL; action.sa_flags = SA_SIGINFO; sigaction(signo, &action, NULL);
This configuration makes these signals suitable for synchronous notification using the sigwaitinfo() function or SignalWaitinfo() kernel call. The following code will block until the eighth special signal is received:
sigset_t *set;
siginfo_t info;
sigemptyset(&set);
sigaddset(&set, SIGRTMAX + 8);
sigwaitinfo(&set, &info);
printf("Received signal %d with code %d and value %d\n",
info.si_signo,
info.si_code,
info.si_value.sival_int);
Since the signals are always blocked, the program cannot be interrupted or killed if the special signal is delivered outside of the sigwaitinfo() function. Since signal queuing is always enabled, signals won't be lost — they'll be queued for the next sigwaitinfo() call.
These signals were designed to solve a common IPC requirement where a server wishes to notify a client that it has information available for the client. The server will use the MsgDeliverEvent() call to notify the client. There are two reasonable choices for the event within the notification: pulses or signals.
A pulse is the preferred method for a client that may also be a server to other clients. In this case, the client will have created a channel for receiving messages and can also receive the pulse.
This won't be true for most simple clients. In order to receive a pulse, a simple client would be forced to create a channel for this express purpose. A signal can be used in place of a pulse if the signal is configured to be synchronous (i.e. the signal is blocked) and queued — this is exactly how the special signals are configured. The client would replace the MsgReceive() call used to wait for a pulse on a channel with a simple sigwaitinfo() call to wait for the signal.
This signal mechanism is used by Photon to wait for events and by the select() function to wait for I/O from multiple servers. Of the eight special signals, the first two have been given special names for this use.
#define SIGSELECT (SIGRTMAX + 1) #define SIGPHOTON (SIGRTMAX + 2)
| Signal | Description |
|---|---|
| SIGABRT | Abnormal termination signal such as issued by the abort() function. |
| SIGALRM | Timeout signal such as issued by the alarm() function. |
| SIGBUS | Indicates a memory parity error (QNX-specific interpretation). Note that if a second fault occurs while your process is in a signal handler for this fault, the process will be terminated. |
| SIGCHLD | Child process terminated. The default action is to ignore the signal. |
| SIGCONT | Continue if HELD. The default action is to ignore the signal if the process isn't HELD. |
| SIGDEADLK | Mutex deadlock occurred. If you haven't called SyncMutexEvent(), and if the conditions that would cause the kernel to deliver the event occur, then the kernel delivers a SIGDEADLK instead. |
| SIGEMT | EMT instruction (emulator trap). |
| SIGFPE | Erroneous arithmetic operation (integer or floating point), such as division by zero or an operation resulting in overflow. Note that if a second fault occurs while your process is in a signal handler for this fault, the process will be terminated. |
| SIGHUP | Death of session leader, or hangup detected on controlling terminal. |
| SIGILL | Detection of an invalid hardware instruction. Note that if a second fault occurs while your process is in a signal handler for this fault, the process will be terminated. |
| SIGINT | Interactive attention signal (Break). |
| SIGIOT | IOT instruction (not generated on x86 hardware). |
| SIGKILL | Termination signal — should be used only for emergency situations. This signal cannot be caught or ignored. |
| SIGPIPE | Attempt to write on a pipe with no readers. |
| SIGPOLL | Pollable event occurred. |
| SIGQUIT | Interactive termination signal. |
| SIGSEGV | Detection of an invalid memory reference. Note that if a second fault occurs while your process is in a signal handler for this fault, the process will be terminated. |
| SIGSTOP | Stop process (the default). This signal cannot be caught or ignored. |
| SIGSYS | Bad argument to system call. |
| SIGTERM | Termination signal. |
| SIGTRAP | Unsupported software interrupt. |
| SIGTSTP | Stop signal generated from keyboard. |
| SIGTTIN | Background read attempted from control terminal. |
| SIGTTOU | Background write attempted to control terminal. |
| SIGURG | Urgent condition present on socket. |
| SIGUSR1 | Reserved as application-defined signal 1. |
| SIGUSR2 | Reserved as application-defined signal 2. |
| SIGWINCH | Window size changed. |
POSIX defines a set of nonblocking message-passing facilities known as message queues. Like pipes, message queues are named objects that operate with “readers” and “writers.” As a priority queue of discrete messages, a message queue has more structure than a pipe and offers applications more control over communications.
|
To use POSIX message queues in QNX Neutrino, the message
queue server must be running.
QNX Neutrino has two implementations of message queues:
For more information about these implementations, see the Utilities Reference. |
Unlike our inherent message-passing primitives, the POSIX message queues reside outside the kernel.
POSIX message queues provide a familiar interface for many realtime programmers. They are similar to the “mailboxes” found in many realtime executives.
There's a fundamental difference between our messages and POSIX message queues. Our messages block — they copy their data directly between the address spaces of the processes sending the messages. POSIX messages queues, on the other hand, implement a store-and-forward design in which the sender need not block and may have many outstanding messages queued. POSIX message queues exist independently of the processes that use them. You would likely use message queues in a design where a number of named queues will be operated on by a variety of processes over time.
For raw performance, POSIX message queues will be slower than QNX Neutrino native messages for transferring data. However, the flexibility of queues may make this small performance penalty worth the cost.
Message queues resemble files, at least as far as their interface is concerned. You open a message queue with mq_open(), close it with mq_close(), and destroy it with mq_unlink(). And to put data into (“write”) and take it out of (“read”) a message queue, you use mq_send() and mq_receive().
For strict POSIX conformance, you should create message queues that start with a single slash (/) and contain no other slashes. But note that we extend the POSIX standard by supporting pathnames that may contain multiple slashes. This allows, for example, a company to place all its message queues under its company name and distribute a product with increased confidence that a queue name will not conflict with that of another company.
In QNX Neutrino, all message queues created will appear in the filename space under the directory:
For example, with the traditional implementation:
| mq_open() name: | Pathname of message queue: |
|---|---|
| /data | /dev/mqueue/data |
| /acme/data | /dev/mqueue/acme/data |
| /qnx/data | /dev/mqueue/qnx/data |
You can display all message queues in the system using the ls command as follows:
ls -Rl /dev/mqueue
The size printed is the number of messages waiting.
POSIX message queues are managed via the following functions:
| Function | Description |
|---|---|
| mq_open() | Open a message queue. |
| mq_close() | Close a message queue. |
| mq_unlink() | Remove a message queue. |
| mq_send() | Add a message to the message queue. |
| mq_receive() | Receive a message from the message queue. |
| mq_notify() | Tell the calling process that a message is available on a message queue. |
| mq_setattr() | Set message queue attributes. |
| mq_getattr() | Get message queue attributes. |
Shared memory offers the highest bandwidth IPC available. Once a shared-memory object is created, processes with access to the object can use pointers to directly read and write into it. This means that access to shared memory is in itself unsynchronized. If a process is updating an area of shared memory, care must be taken to prevent another process from reading or updating the same area. Even in the simple case of a read, the other process may get information that is in flux and inconsistent.
To solve these problems, shared memory is often used in conjunction with one of the synchronization primitives to make updates atomic between processes. If the granularity of updates is small, then the synchronization primitives themselves will limit the inherently high bandwidth of using shared memory. Shared memory is therefore most efficient when used for updating large amounts of data as a block.
Both semaphores and mutexes are suitable synchronization primitives for use with shared memory. Semaphores were introduced with the POSIX realtime standard for interprocess synchronization. Mutexes were introduced with the POSIX threads standard for thread synchronization. Mutexes may also be used between threads in different processes. POSIX considers this an optional capability; we support it. In general, mutexes are more efficient than semaphores.
Shared memory and message passing can be combined to provide IPC that offers:
Using message passing, a client sends a request to a server and blocks. The server receives the messages in priority order from clients, processes them, and replies when it can satisfy a request. At this point, the client is unblocked and continues. The very act of sending messages provides natural synchronization between the client and the server. Rather than copy all the data through the message pass, the message can contain a reference to a shared-memory region, so the server could read or write the data directly. This is best explained with a simple example.
Let's assume a graphics server accepts draw image requests from clients and renders them into a frame buffer on a graphics card. Using message passing alone, the client would send a message containing the image data to the server. This would result in a copy of the image data from the client's address space to the server's address space. The server would then render the image and issue a short reply.
If the client didn't send the image data inline with the message, but instead sent a reference to a shared-memory region that contained the image data, then the server could access the client's data directly.
Since the client is blocked on the server as a result of sending it a message, the server knows that the data in shared memory is stable and will not change until the server replies. This combination of message passing and shared memory achieves natural synchronization and very high performance.
This model of operation can also be reversed — the server can generate data and give it to a client. For example, suppose a client sends a message to a server that will read video data directly from a CD-ROM into a shared memory buffer provided by the client. The client will be blocked on the server while the shared memory is being changed. When the server replies and the client continues, the shared memory will be stable for the client to access. This type of design can be pipelined using more than one shared-memory region.
Simple shared memory can't be used between processes on different computers connected via a network. Message passing, on the other hand, is network transparent. A server could use shared memory for local clients and full message passing of the data for remote clients. This allows you to provide a high-performance server that is also network transparent.
In practice, the message-passing primitives are more than fast enough for the majority of IPC needs. The added complexity of a combined approach need only be considered for special applications with very high bandwidth.
Multiple threads within a process share the memory of that process. To share memory between processes, you must first create a shared-memory region and then map that region into your process's address space. Shared-memory regions are created and manipulated using the following calls:
| Function | Description | Classification |
|---|---|---|
| shm_open() | Open (or create) a shared-memory region. | POSIX |
| close() | Close a shared-memory region. | POSIX |
| mmap() | Map a shared-memory region into a process's address space. | POSIX |
| munmap() | Unmap a shared-memory region from a process's address space. | POSIX |
| munmap_flags() | Unmap previously mapped addresses, exercising more control than possible with munmap() | QNX Neutrino |
| mprotect() | Change protections on a shared-memory region. | POSIX |
| msync() | Synchronize memory with physical storage. | POSIX |
| shm_ctl(), shm_ctl_special() |
Give special attributes to a shared-memory object. | QNX Neutrino |
| shm_unlink() | Remove a shared-memory region. | POSIX |
POSIX shared memory is implemented in QNX Neutrino via the process manager (procnto). The above calls are implemented as messages to procnto (see the Process Manager chapter in this book).
The shm_open() function takes the same arguments as open() and returns a file descriptor to the object. As with a regular file, this function lets you create a new shared-memory object or open an existing shared-memory object.
|
You must open the file descriptor for reading; if you want to write in the memory object, you also need write access, unless you specify a private (MAP_PRIVATE) mapping. |
When a new shared-memory object is created, the size of the object is set to zero. To set the size, you use ftruncate() — the very same function used to set the size of a file — or shm_ctl().
Once you have a file descriptor to a shared-memory object, you use the mmap() function to map the object, or part of it, into your process's address space. The mmap() function is the cornerstone of memory management within QNX Neutrino and deserves a detailed discussion of its capabilities.
|
You can also use mmap() to map files and typed memory objects into your process's address space. |
The mmap() function is defined as follows:
void * mmap( void *where_i_want_it,
size_t length,
int memory_protections,
int mapping_flags,
int fd,
off_t offset_within_shared_memory );
In simple terms this says: “Map in length bytes of shared memory at offset_within_shared_memory in the shared-memory object associated with fd.”
The mmap() function will try to place the memory at the address where_i_want_it in your address space. The memory will be given the protections specified by memory_protections and the mapping will be done according to the mapping_flags.
The three arguments fd, offset_within_shared_memory, and length define a portion of a particular shared object to be mapped in. It's common to map in an entire shared object, in which case the offset will be zero and the length will be the size of the shared object in bytes. On an Intel processor, the length will be a multiple of the page size, which is 4096 bytes.
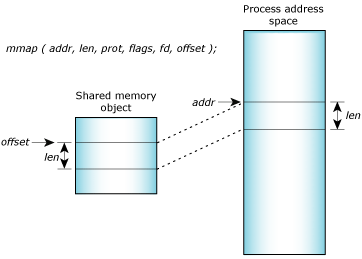
Mapping memory with mmap().
The return value of mmap() will be the address in your process's address space where the object was mapped. The argument where_i_want_it is used as a hint by the system to where you want the object placed. If possible, the object will be placed at the address requested. Most applications specify an address of zero, which gives the system free reign to place the object where it wishes.
The following protection types may be specified for memory_protections:
| Manifest | Description |
|---|---|
| PROT_EXEC | Memory may be executed. |
| PROT_NOCACHE | Memory should not be cached. |
| PROT_NONE | No access allowed. |
| PROT_READ | Memory may be read. |
| PROT_WRITE | Memory may be written. |
You should use the PROT_NOCACHE manifest when you're using a shared-memory region to gain access to dual-ported memory that may be modified by hardware (e.g. a video frame buffer or a memory-mapped network or communications board). Without this manifest, the processor may return “stale” data from a previously cached read.
The mapping_flags determine how the memory is mapped. These flags are broken down into two parts — the first part is a type and must be specified as one of the following:
| Map type | Description |
|---|---|
| MAP_SHARED | The mapping may be shared by many processes; changes are propagated back to the underlying object. |
| MAP_PRIVATE | The mapping is private to the calling process; changes aren't propagated back to the underlying object. The mmap() function allocates system RAM and makes a copy of the object. |
The MAP_SHARED type is the one to use for setting up shared memory between processes; MAP_PRIVATE has more specialized uses.
You can OR a number of flags into the above type to further define the mapping. These are described in detail in the mmap() entry in the Library Reference. A few of the more interesting flags are:
You commonly use MAP_ANON with MAP_PRIVATE, but you can use it with MAP_SHARED to create a shared memory area for forked applications. You can use MAP_ANON as the basis for a page-level memory allocator.
You can use MAP_NOX64K and MAP_BELOW16M to further define the MAP_ANON allocated memory and address limitations present in some forms of DMA.
|
You should use mmap_device_memory() instead of MAP_PHYS, unless you're allocating physically contiguous memory. |
Using the mapping flags described above, a process can easily share memory between processes:
/* Map in a shared memory region */
fd = shm_open("datapoints", O_RDWR);
addr = mmap(0, len, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
or allocate a DMA buffer for a bus-mastering PCI network card:
/* Allocate a physically contiguous buffer */
addr = mmap(0, 262144, PROT_READ|PROT_WRITE|PROT_NOCACHE,
MAP_PHYS|MAP_ANON, NOFD, 0);
You can unmap all or part of a shared-memory object from your address space using munmap(). This primitive isn't restricted to unmapping shared memory — it can be used to unmap any region of memory within your process. When used in conjunction with the MAP_ANON flag to mmap(), you can easily implement a private page-level allocator/deallocator.
You can change the protections on a mapped region of memory using mprotect(). Like munmap(), mprotect() isn't restricted to shared-memory regions — it can change the protection on any region of memory within your process.
POSIX requires that mmap() zero any memory that it allocates. It can take a while to initialize the memory, so QNX Neutrino provides a way to relax the POSIX requirement. This allows for faster starting, but can be a security problem.
|
This feature was added in the QNX Neutrino Core OS 6.3.2. |
Avoiding initializing the memory requires the cooperation of the process doing the unmapping and the one doing the mapping:
int munmap_flags( void *addr, size_t len,
unsigned flags );
Pass one of the following for the flags argument:
By default, the kernel initializes the memory, but you can control this by using the -m option to procnto. The argument to this option is a string that lets you enable or disable aspects of the memory manager:
Note again that munmap_flags() with a flags argument of 0 behaves the same as munmap() does.
Typed memory is POSIX functionality defined in the 1003.1 specification. It's part of the advanced realtime extensions, and the manifests are located in the <sys/mman.h> header file.
Typed memory adds the following functions to the C library:
POSIX typed memory provides an interface to open memory objects (which are defined in an OS-specific fashion) and perform mapping operations on them. It's useful in providing an abstraction between BSP- or board-specific address layouts and device drivers or user code.
POSIX specifies that typed memory pools (or objects) are created and defined in an implementation-specific fashion. This section describes the following for Neutrino:
Under Neutrino, typed memory objects are defined from the memory regions specified in the asinfo section of the system page. Thus, typed memory objects map directly to the address space hierarchy (asinfo segments) define by startup. The typed memory objects also inherit the properties defined in asinfo, namely the physical address (or bounds) of the memory segments.
In general, the naming and properties of the asinfo entries is arbitrary and is completely under the user's control. There are, however, some mandatory entries:
Since by convention sysram is the memory that has been given to the OS, this pool is the same as that used by the OS to satisfy anonymous mmap() and malloc() requests.
You can create additional entries, but only in startup, using the as_add() function.
The names of typed memory regions are derived directly from the names of the asinfo segments. The asinfo section itself describes a hierarchy, and so the naming of typed memory object is a hierarchy. Here's a sample system configuration:
| Name | Range (start, end) |
|---|---|
| /memory | 0, 0xFFFFFFFF |
| /memory/ram | 0, 0x1FFFFFF |
| /memory/ram/sysram | 0x1000, 0x1FFFFFF |
| /memory/isa/ram/dma | 0x1000, 0xFFFFFF |
| /memory/ram/dma | 0x1000, 0x1FFFFFF |
The name you pass to posix_typed_mem_open() follows the above naming convention. POSIX allows an implementation to define what happens when the name doesn't start with a leading slash (/). The resolution rules on opening are as follows:
Here are some examples of how posix_typed_mem_open() resolves names, using the above sample configuration:
| This name: | Resolves to: | See: |
|---|---|---|
| /memory | /memory | Rule 1 |
| /memory/ram | /memory/ram | Rule 2 |
| /sysram | Fails | |
| sysram | /memory/ram/sysram | Rule 3 |
The typed memory name hierarchy is exported through the process manager namespace under /dev/tymem. Applications can list this hierarchy, and look at the asinfo entries in the system page to get information about the typed memory.
|
Unlike for shared memory objects, you can't open typed memory through the namespace interface, because posix_typed_mem_open() takes the additional parameter tflag, which is required and isn't provided in the open() API. |
The following general cases of allocations and mapping are considered for typed memory:
mmap(0, 0x1000, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANON,
NOFD, 0);
The memory is allocated and not available for other allocations, but if you fork the process, the child processes can access it as well. The memory is released when the last mapping to it is removed.
Note that like somebody doing mem_offset() and then a MAP_PHYS to gain access to previously allocated memory, somebody else could open the typed memory object with POSIX_TYPED_MEMORY_ALLOCATABLE (or with no flags) and gain access to the same physical memory that way.
POSIX_TYPED_MEM_ALLOC_CONTIG is like MAP_ANON | MAP_SHARED, in that it causes a contiguous allocation.
You should use only MAP_SHARED mappings, since a write to a MAP_PRIVATE mapping will (as normal) create a private copy for the process in normal anonymous memory.
If you specify no flag, or you specify POSIX_TYPED_MEM_MAP_ALLOCATABLE, the offset parameter to mmap() specifies the starting physical address in the typed memory region; if the typed memory region is discontiguous (multiple asinfo entries), the allowed offset values are also discontiguous and don't start at zero as they do for shared memory objects. If you specify a [paddr, paddr + size) region that falls outside the allowed addresses for the typed memory object, mmap() fails with ENXIO.
Permissions on a typed memory object are governed by UNIX permissions. The oflags argument to posix_typed_mem_open() specifies the desired access privilege, and these flags are checked against the permission mask of the typed memory object.
POSIX doesn't specify how permissions are assigned to the typed memory objects. Under Neutrino, default permissions are assigned at system boot-up. By default, root is the owner and group, and has read-write permissions; no one else has any permissions.
Currently, there's no mechanism to change the permissions of an object. In the future, the implementation may be extended to allow chmod() and chown() to modify the permissions.
You can retrieve the size of an object by using posix_typed_mem_get_info(). This call fills in a posix_typed_mem_info structure, which includes the posix_tmi_length field, which contains the size of the typed memory object.
As specified by POSIX, the length field is dynamic and contains the current allocatable size for that object (in effect, the free size of the object for POSIX_TYPED_MEM_ALLOCATE and POSIX_TYPED_MEM_ALLOCATE_CONTIG). If you opened the object with a tflag of 0 or POSIX_TYPED_MEM_ALLOCATABLE, the length field is set to zero.
When you map in a typed memory object, you usually pass an offset to mmap(). The offset is the physical address of the location in the object where the mapping should commence. The offset is appropriate only when opening the object with a tflag of 0 or POSIX_TYPED_MEM_ALLOCATABLE. If you opened the typed memory object with POSIX_TYPED_MEM_ALLOCATE or POSIX_TYPED_MEM_ALLOCATE_CONTIG, a nonzero offset causes the call to mmap() to fail with an error of EINVAL.
int fd = posix_typed_mem_open( "/memory/ram/sysram", O_RDWR,
POSIX_TYPED_MEM_ALLOCATE_CONTIG);
unsigned vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,
MAP_PRIVATE, fd, 0);
Assume you have special memory (say fast SRAM) that you want to use for packet memory. This SRAM isn't put in the global system RAM pool. Instead, in startup, we use as_add() (see the Customizing Image Startup Programs chapter of Building Embedded Systems) to add an asinfo entry for the packet memory:
as_add(phys_addr, phys_addr + size - 1, AS_ATTR_NONE,
"packet_memory", mem_id);
where phys_addr is the physical address of the SRAM, size is the SRAM size, and mem_id is the ID of the parent (typically memory, which is returned by as_default()).
This code creates an asinfo entry for packet_memory, which you can then use as POSIX typed memory. The following code allows different applications to allocate pages from packet_memory:
int fd = posix_typed_mem_open( "packet_memory", O_RDWR,
POSIX_TYPED_MEM_ALLOCATE);
unsigned vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
Alternatively, you may want to use the packet memory as direct shared, physical buffers. In this case, applications would use it as follows:
int fd = posix_typed_mem_open( "packet_memory", O_RDWR,
POSIX_TYPED_MEM_ALLOCATABLE);
unsigned vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,
MAP_SHARED, fd, offset);
On some hardware, due to limitations of the chipset or memory controller, it may not be possible to perform DMA to arbitrary addresses in the system. In some cases, the chipset has only the ability to DMA to a subset of all physical RAM. This has traditionally been difficult to solve without statically reserving some portion of RAM of driver DMA buffers (which is potentially wasteful). Typed memory provides a clean abstraction to solve this issue. Here's an example:
In startup, use as_add_containing() (see the Customizing Image Startup Programs chapter of Building Embedded Systems) to define an asinfo entry for DMA-safe memory. Make this entry be a child of ram:
as_add_containing( dma_addr, dma_addr + size - 1,
AS_ATTR_RAM, "dma", "ram");
where dma_addr is the start of the DMA-safe RAM, and size is the size of the DMA-safe region.
This code creates an asinfo entry for dma, which is a child of ram. Drivers can then use it to allocate DMA-safe buffers:
int fd = posix_typed_mem_open( "ram/dma", O_RDWR,
POSIX_TYPED_MEM_ALLOCATE_CONTIG);
unsigned vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
A pipe is an unnamed file that serves as an I/O channel between two or more cooperating processes—one process writes into the pipe, the other reads from the pipe. The pipe manager takes care of buffering the data. The buffer size is defined as PIPE_BUF in the <limits.h> file. A pipe is removed once both of its ends have closed. The function pathconf() returns the value of the limit.
Pipes are normally used when two processes want to run in parallel, with data moving from one process to the other in a single direction. (If bidirectional communication is required, messages should be used instead.)
A typical application for a pipe is connecting the output of one program to the input of another program. This connection is often made by the shell. For example:
ls | more
directs the standard output from the ls utility through a pipe to the standard input of the more utility.
| If you want to: | Use the: |
|---|---|
| Create pipes from within the shell | pipe symbol (“|”) |
| Create pipes from within programs | pipe() or popen() functions |
FIFOs are essentially the same as pipes, except that FIFOs are named permanent files that are stored in filesystem directories.
| If you want to: | Use the: |
|---|---|
| Create FIFOs from within the shell | mkfifo utility |
| Create FIFOs from within programs | mkfifo() function |
| Remove FIFOs from within the shell | rm utility |
| Remove FIFOs from within programs | remove() or unlink() function |
|
|
|
|