![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
In this chapter:
The System Profiler is a tool that works in concert with the Neutrino instrumented kernel (procnto-instr) to provide insight into the operating system's events and activities. Think of the System Profiler as a system-level software logic analyzer. Like the Application Profiler, the System Profiler can help pinpoint areas that need improvement, but at a system-wide level.
The instrumented kernel can gather a variety of events, including:
You might use the System Profiler to solve such problems as:
 |
Details on kernel instrumentation (such as types and classes of events) are more fully covered in the System Analysis Toolkit (SAT) User's Guide. |
The QNX System Profiler perspective includes several components that are relevant to system profiling:
|
You can gather statistics for the entire log file or for a selected range. |
Other components help you determine why a given thread is running, examine the migration of threads from one processor or core to another, and so on. For more details, see “Associated views,” later in this chapter.
|
The QNX System Profiler perspective may produce incorrect results when more than one IDE is communicating with the same target system. To use this perspective, make sure only one IDE is connected to the target system. |
You can perform heap memory profiling to achieve two goals: performance improvements (because heap memory allocation/deallocation is one of the most expensive ways of obtaining memory), and heap memory optimization. The QNX Momentics Memory Analysis tool can assist you with both of these goals.
|
Before you begin to profile, your application should run without memory errors. You can use the IDE tools to find memory errors. For information about these tools, see “Finding Memory Errors”. |
As mentioned earlier, to capture instrumentation data for analysis, the instrumented kernel (procnto-instr) must be running. This kernel is a drop-in replacement for the standard kernel (though the instrumented kernel is slightly larger). When you're not gathering instrumentation data, the instrumented kernel is almost exactly as fast as the regular kernel.
|
To determine if the instrumented kernel is running, enter this
command:
ls /proc/boot If procnto-instr appears in the output, then the OS image is running the instrumented kernel. |
To substitute the procnto-instr module in the OS image on your board, you can either manually edit your buildfile, then run mkifs to generate a new image, or use the System Builder perspective to configure the image's properties.
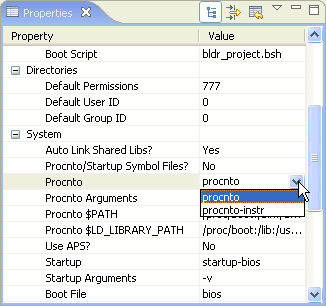
Assuming you're running the instrumented kernel on your board, you're ready to use the System Profiler. A profiling session usually involves these three steps:
You can gather trace events from the instrumented kernel in two different ways. You can run a command-line utility (e.g. tracelogger) on your target to generate a log file, and then transfer that log file back to your development environment for analysis. Or, you can capture events directly from the IDE using the Log Configuration dialog.
|
In order to get timing information from the kernel, you need
to run tracelogger as the root user.
If you gather system-profiling data through qconn in the IDE, you're already accessing the instrumented kernel as root. |
Using the command-line server currently offers more flexibility as to when the data is captured, but requires that you set up and configure filters yourself using the TraceEvent() API. The Log Configuration dialog lets you set a variety of different static filters and configure the duration of time that the events are logged for.
For more information on the tracelogger utility, see its entry in the Utilities Reference. For TraceEvent(), see the Neutrino Library Reference.
|
If you don't already have a target project, you'll have to create one. To create a target project:
You can use this target project for a number of different tasks (debugging, memory analysis, profiling), so once you create it, you won't have to worry about connecting to your target again. Note also that the qconn target agent must be running on your target machine. |
The Log Configuration dialog takes you through the process of selecting:
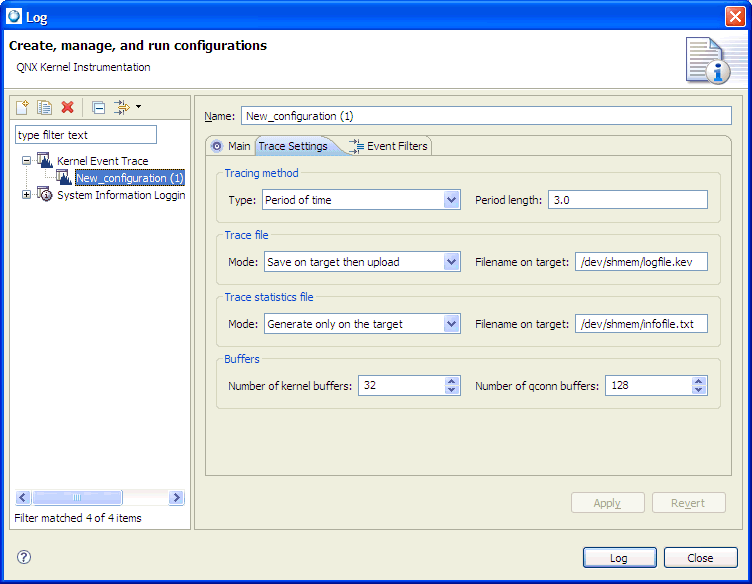
Capturing event-specific information using kernel logging.
Here are the main fields in this wizard:
|
If your target is running earlier versions of QNX Neutrino, you must use this option instead of “Generate only on the target” because the trace statistics file is not supported on versions such as QNX Neutrino 6.2.1. |
Regardless of how your log file is captured, you have a number of different options for regulating the amount of information actually captured:
(For more information, see the SAT User's Guide.)
The IDE lets you access the first three of the above filters. You can enable tracing (currently done by activating the Log Configuration dialog), and then select what kind of data is logged for various events in the system.
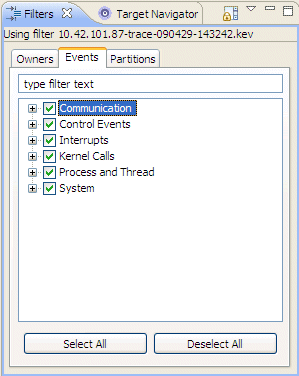
The events in the system are organized into different classes (kernel calls, communication, thread states, interrupts, etc.). You can toggle each of these classes in order to indicate whether or not you want to generate such events for logging.
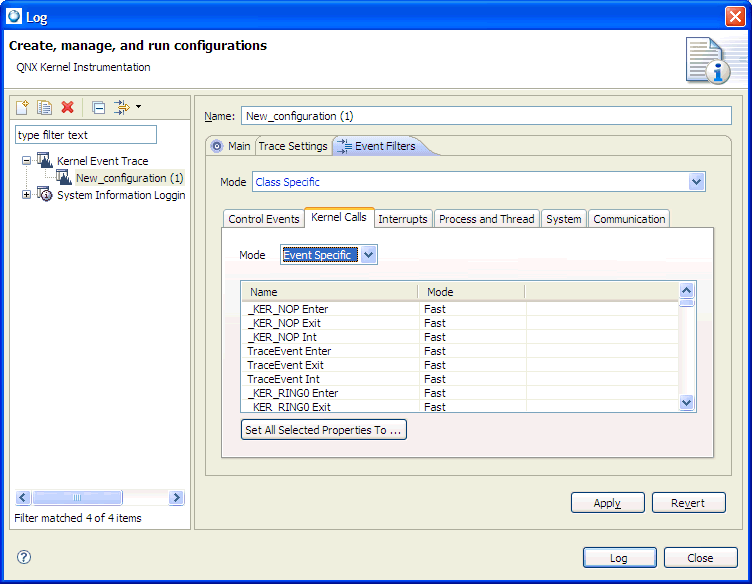
The data logged with events comes in the following modes:
Choosing Event Specific lets you select Disable, Fast, or Wide for each event in that class.
Depending on the purpose of the trace, you'll want to selectively enable different tracing modes for different types of events so as to minimize the impact on the overall system. For its part in the analysis of these events, the IDE does its best to work with whatever data is present. (But note that some functionality may not be available for post-capture analysis if it isn't present in the raw event log. ;-))
The IDE lets you import only a portion of a kernel trace into Application Profiler; however, you can also continue to import the entire kernel trace, if required. When you use the import action from the System Profiler editor, only the portion of the kernel trace that is currently selected will be imported into the Application Profiler. This means that the Application Profiler only considers a single process from the trace; it chooses the process that is associated with the binary selected by the user.
To import a selected portion of the kernel trace into Application Profiler:
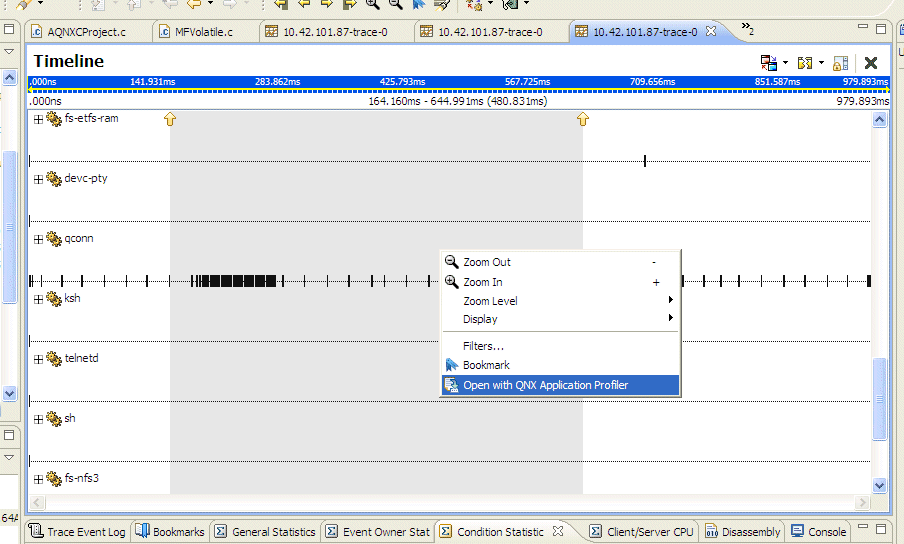
After you select the menu option, the Import dialog is displayed.
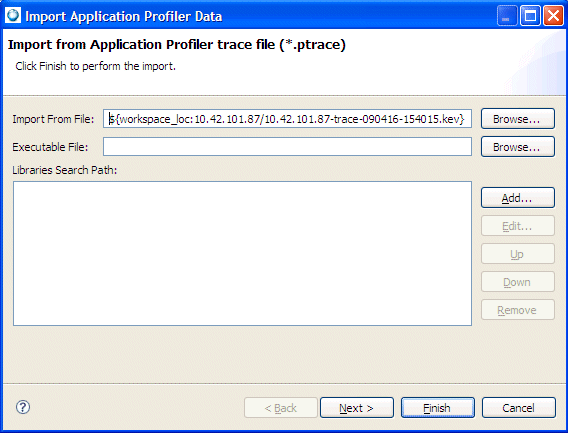
The IDE opens the Application Profiler perspective.
Once an event file is generated and transferred back to the development host for analysis (whether it was done automatically by the IDE or generated by using tracelogger and manually extracted back to the IDE), you can then invoke the System Profiler editor.
Log files are loaded in a nonmodal activity that you can cancel. This lets you load multiple log files at the same time, and log file data can be normalized as a background task when it's out of order. The view shows data up to the point where the log file was processed.
|
If you receive a “Could not find target: Read timed out”
error while capturing data, it's possible that a CPU-intensive program
running at a priority the same as or higher than qconn is
preventing qconn from transferring data back to the host
system.
If this happens, restart qconn with the qconn_prio= option to specify a higher priority. You can use hogs or pidin to see which process is keeping the target busy, and discover its priority. |
The IDE includes a custom perspective for working with the System Profiler. This perspective sets up some of the more relevant views for easy access.
Searches in the System Profiler occur in the background, with results shown as they're found. The results of each search operation are managed separately and are “overlaid” on top of one another, allowing multiple search results to be graphically viewed together in the System Profiler Timeline editor pane.
You can configure the table that's shown in the search result view to show only the interesting trace event fields. The content of this table can be cut and pasted to the system clipboard as CSV-format data.
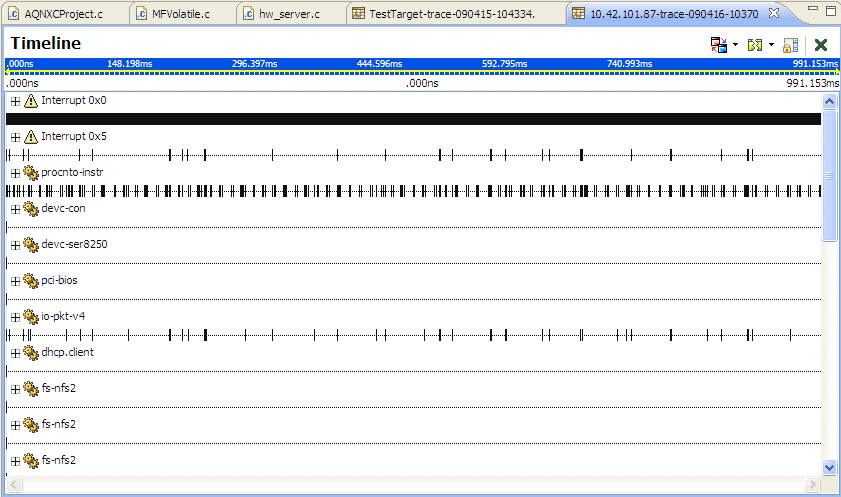
The System Profiler's Timeline view.
Timeline event labels let distinguish between different types of events (the label only shows the data for the event and its type). In addition, you can also set the Timeline view to display address translation information, such as function name. By using event labels, you can quickly differentiate between different types of events, or display multiple data values for the same event. The purpose of event labels is to annotate function entry and exit events in the Timeline pane with their corresponding function names.
To access the label options, select the Toggle Labels icon in the System Profiler perspective:
![]()
The Timeline event label data selection dialog is available by clicking the Toggle labels icon, and then selecting Configuring Event Labels:
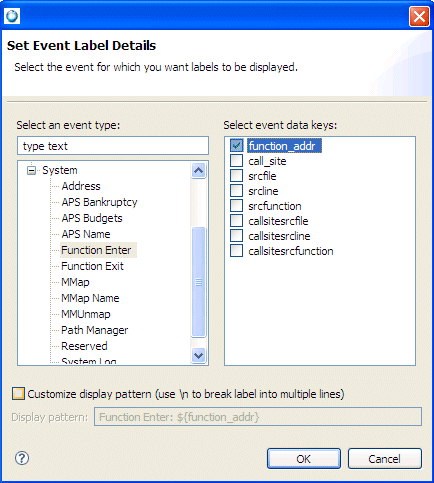
Setting event labels in the System Profiler's Timeline view.
The data selection list lets you select multiple data keys. In addition, the dialog lets you define whether you want to customize the display pattern for the corresponding label. By default, a default display pattern is provided and consists of the event type label, followed by a comma separated list of data keys. The display pattern supports the following replacement patterns:
For a list of event data keys specific to address translation, see “Address translation.”
The Timeline event preference page and the property page show the new properties of the labels (select and then expand and select Timeline Event labels):
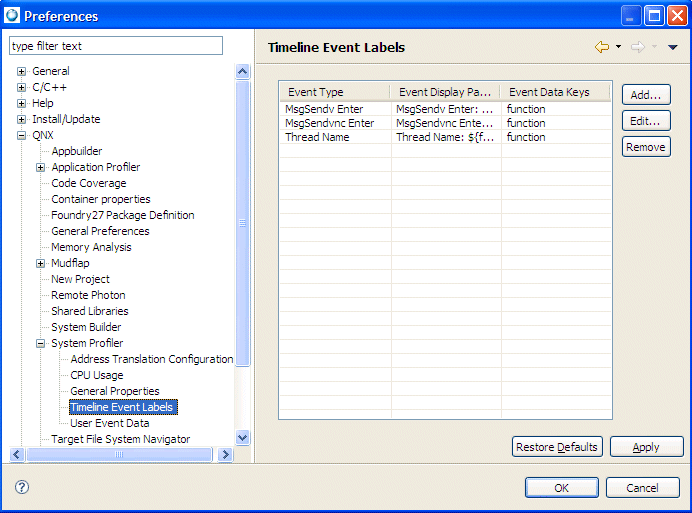
Setting preferences for the System Profiler's Timeline view.
Once you specify any event labels, the Timeline view shows the display pattern for the label and displays multiple keys.
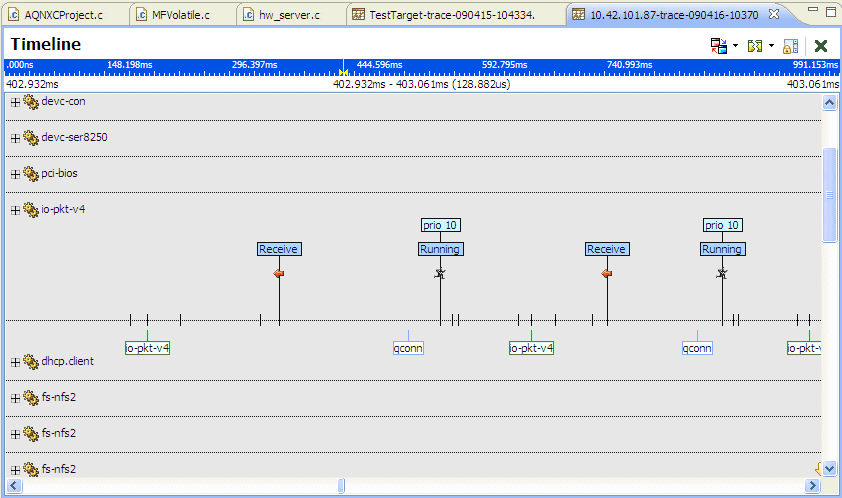
The System Profiler's Timeline view that includes labels.
In the Preferences dialog, click Edit to edit any existing labels, or click Add to select an event type for which a label had already been defined. Any changes you make change the previously defined label, for which you'll receive a notification message.
|
The IDE performs kernel tracing events as background tasks. You can monitor the progress of the trace by opening the Progress view. |
In the System Profiler editor's Timeline view, you can navigate to the next or previous event for a specific event owner only. This lets you follow a sequence of events generated by a particular set of event owners (for example finding the next event owned by a thread, or the messages generated by a client and server).
In locations where single events have been identified (for example, the Trace Log view, Search Results view), you can navigate directly to the event location in the System Profiler Timeline editor pane by double-clicking. The selection marker is moved to the event location and, if possible, the specific event owner is scrolled into view in the Timeline editor pane.
The Navigate menu contains a Go To Event command that lets you jump directly to a specific event. This command allows developers to collaborate more easily with one another by providing direct event navigation by event index, event cycle, or natural time.
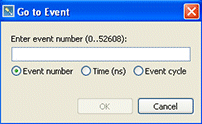
The System Profiler's Go To Event command.
These components of the QNX System Profiler are described in detail later in this chapter:
You can set your address translation information within the Kernel Event Trace Log launch configuration.
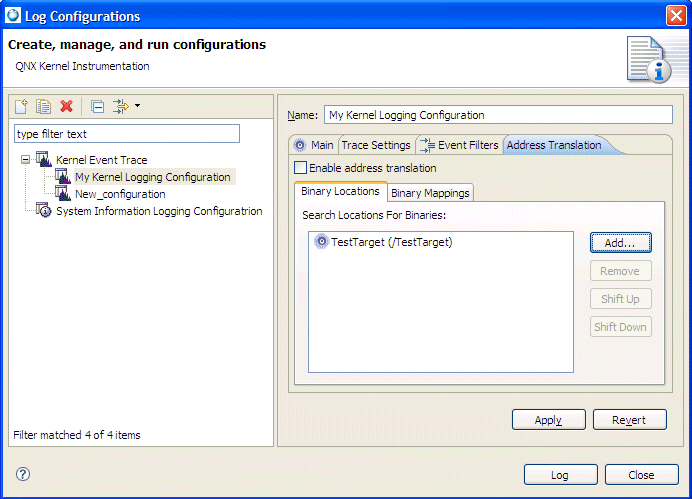
Address translation in Log Configuration dialog.
To enable address translation:
The address translation Binary Locations lets you specify the search locations to use for your binaries.
The Binary Mappings tab lets you specify the name of your binary (it will use the default load address). Click Add Binary to manually provide a binary name if your binary is not found. If you click Import, the Address Translation's pidin mem import lets you import only binaries that are contained within the defined binary search paths.
|
You can use the output from pidin to populate the binary mappings. The output will help you determine the load addresses of any libraries your application is using. To use this output, while your application is running, run the pidin command with the mem option, and output the results to a file (i.e. pidin mem > pidin_results). Use the Import button to select the results file. For Address translation (for interrupt IP events), the log file must be matched with the binary files in your workspace for address decoding to occur. When a new kernel trace that contains address translation information is generated using Kernel Event Trace logging, the kernel trace automatically contains the address translation information. If you launch an application using a launch configuration that has the Kernel Logging tool enabled, the address translation information for the generated kernel trace comes from the settings of the Kernel Event Trace configuration (specified by the Kernel Logging tool). Additionally, address translation information for the binary being launched will be added to the kernel trace (set using , and then select ). |
The Trace Event Label selection dialog includes address translation related keys (select System on the Select Event Data Key dialog) for Function Entry and Function Exit events. These address translation keys are:
Address translation allows for the automatic discovery of library load addresses by analyzing the log file for events. By default, the Add Library dialog in the Address Translation dialog lets you specify that the library address should be discovered automatically. When kernel logging is used in conjunction with a C/C++ launch configuration and the Application Profiler tool, address translation for the generated kernel trace will have address translation information.
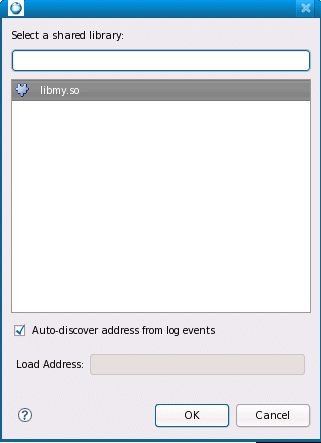
Address translation: adding a library.
If you open a log file that has address translation information with libraries set to auto-discover, the log file will be analyzed and the library addresses determined for address translation. If library addresses are discovered, they're persisted to the trace log so that the lookup doesn't occur the next time you open the log. If the auto-discovery of library addresses isn't successful (i.e. generation of MMAPNAME events was disabled in the kernel trace log launch configuration), you'll receive a warning that you'll need to manually set this information.
You have the option to disable the warning, or by using the System Profiler address translation preference page (set using , and then select , and set the option Provide a warning if address translation auto-discovery fails while opening a trace log):
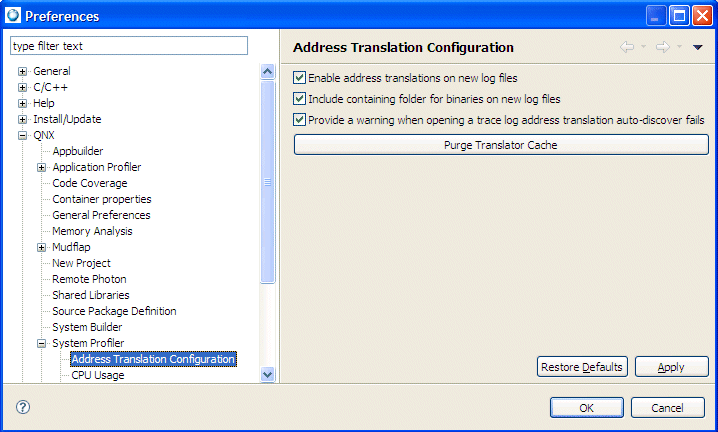
Setting preferences for address translation.
The libraries associated with the launch are also added to the address translation, along with the binary. These libraries will be set to auto-discover, meaning that under most scenarios when running a C/C++ launch in combination with the Application Profiler and System Profiler tools, address translation will automatically function without requiring user intervention.
Invoked by Ctrl-H (or via ), this panel lets you execute more complex event queries than are possible with the Find dialog.
You can define conditions, which may include regular expressions for matching particular event data content (e.g. all MsgSend events whose calling function corresponds to mmap()). You can then evaluate these conditions and place annotations directly into the System Profiler editor. The results are shown in the Search view.
Unlike the other search panels in the IDE, the Trace Search panel can search for events only in the currently active System Profiler editor. You use this search panel to build conditions and then combine them into an expression. A search iterates through the events from the active log file and is applied against the expression; any “hits” appear in the Search Results view and are highlighted in the System Profiler editor.
By default, the Trace Search panel returns up to 1000 hits. You can change this maximum in the Preferences dialog (choose ).
This view shows the properties for selected objects.
This Properties view will show information about the log file that was captured, such as the date and time, as well as the machine the log file was captured on.
The IDE lets you filter profile data so that you can look at a subset of the captured information. You can specify filtering on the following items:
To filter profile data:
Notice that the Timeline will dynamically change (for the specified time range) based on the filtering selections you make.
You can use the data from the Function Instrumentation mode in System Profiler. For information about the benefits of using Function Instrumentation mode and for instructions about using this feature, see “Using Function Instrumentation in the System Profiler.”
The QNX System Profiler perspective includes the following views:
The IDE includes partition-based filtering that lets editor panes and views support filtering to show only data related to the partitions that you select. If a pane or view supports filtering, The IDE updates the display as the filters change.
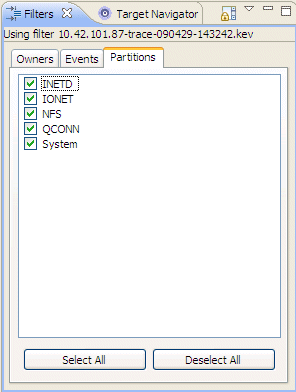
Using partition filters to filter data based on selected partitions.
The statistics views (such as General Statistics view, Client/Server CPU Statistics view, Condition Statistics view, and Event Owner Statistics view ) support filtering based on selected items in the Filters view. You can toggle an option to indicate whether filtering should take place. The IDE updates the Status Bar to indicate whether the results are being filtered.
In order to start examining an event file, the easiest way is to name it with a .kev (kernel event) extension. Files with this extension are automatically bound to the System Profiler editor.
The System Profiler editor is the center of all of the analysis activity. It provides different visualization options for the event data in the log files:
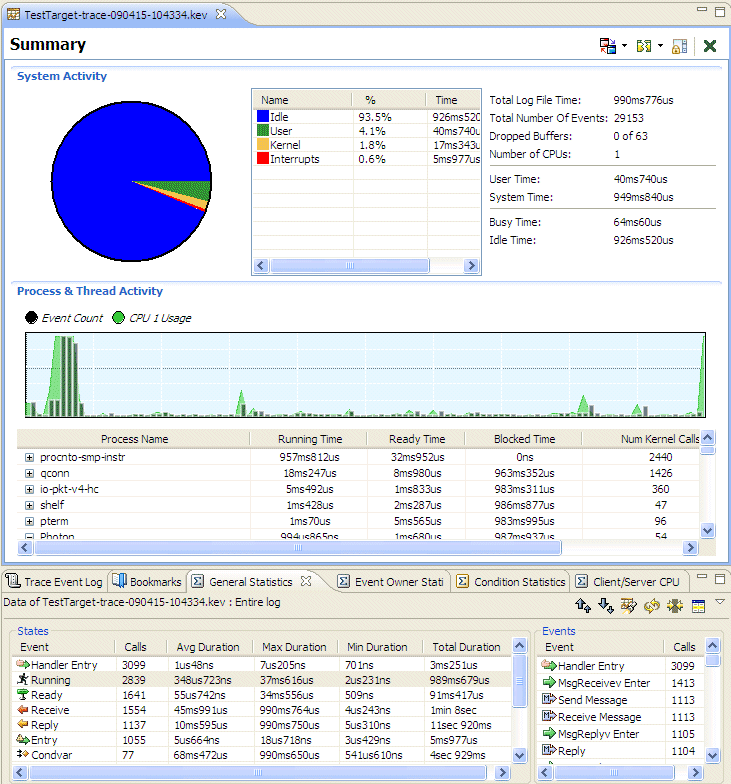
The System Profiler editor.
The System Profiler editor panes include the following:
The IDE generates an overview of the CPU and trace event activity over the period of the log file. This overview contains the same information displayed in the Overview view.
The process activity (amount of time spent RUNNING or READY, number of kernel calls) displayed in the Summary pane contains the same information as can be extracted by drilling down for a particular time range of the event log using the General Statistics view and the Event Owner Statistics view
The Summary pane is on by default. To choose one of the other types, right-click in the editor, then select , or click this icon:
![]()
You can choose a specific display type from the dropdown menu associated with this menu item or icon.
For the CPU Activity pane is not customizable. The CPU Usage pane is configurable (the graph types are line and area) by selecting .
3D versions of each chart are also available.
Each of these visualizations is available as a “pane” in a stack of “panes.” Additionally, the visualization panes can be split — you can look at the different sections of the same log file and do comparative analysis.
All panes of the same stack share the same display information. A new pane inherits the display information from the previous pane, but becomes independent after it's created.
To split the display, right-click in the editor, then select , or click this icon:
![]()
You can lock two panes to each other. From the Split Display submenu, choose the graph you want to display in the new pane, or click this icon:
![]()
|
You can have a maximum of four panes displayed at once. |
For the Timeline pane, a number of different features are available from within the editor:
If an owner has children (e.g. a parent process with threads), you'll see a plus sign beside the parent's name. To see a parent's children, click the plus sign.
For example, to view only processes that are sending pulses, choose to open the Filters view. Select the Events tab, and then replace type filter text with MsgSend. Click Deselect All, and then click the applicable MsgSend events that your search found. The selected events are added to your display dynamically.
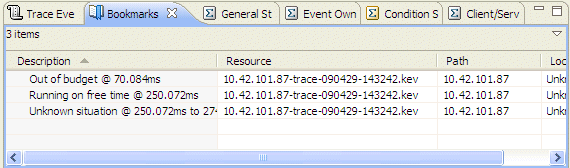
These bookmarks show up in the Bookmarks view and can represent a range of time or a single particular event instance.
You can toggle IPC tracing on/off by clicking this button in the toolbar:
![]()
By default, this displays the IPC trace arrows for all event owners. You can choose to display only the arrows for the selected owners by choosing Selection from the button's dropdown menu.
If you haven't expanded a process in the display, the labels for all of its threads are displayed. By default, no labels are displayed.
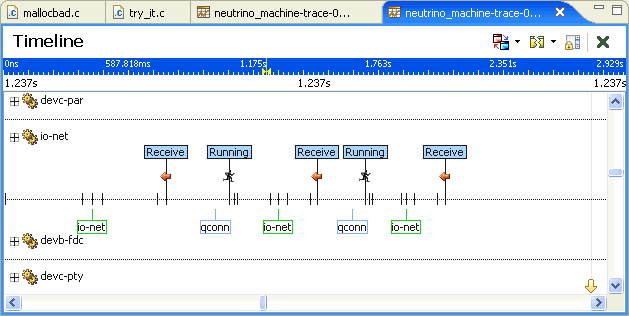
For the Timeline pane, within the editor you can select either of the following:
To select a single owner, simply click the owner's name. To unselect an owner, press and hold the Ctrl key, then click each selected owner's name.
To select multiple owners, press and hold the Ctrl key, then click each owner's name.
To select a point in time, click an event on the timeline.
To select a range, click the start point on the timeline, then drag and release at the end point.
Or, select the start point, then hold down the Shift key and select the end point.
When zooming in, the display centers the selection. If a time-range selection is smaller than the current display, the display adjusts to the range selection (or by a factor of two).
When zooming out, the display centers the selection and adjusts by a factor of two.
When using a preset zoom factor (100% to 0.01%), the display centers the current selection and adjusts to the new factor.
There are various ways to zoom:
You can use these keys to scroll through time:
| To move: | Use this key: |
|---|---|
| The selection to the left by one event | Ctrl-← |
| The selection to the right by one event | Ctrl-→ |
| The display to the left | ← |
| The display to the right | → |
| The selection for the current owner to the left by one event | Ctrl-Shift-← |
| The selection for the current owner to the right by one event | Ctrl-Shift-→ |
You can use these keys to scroll through the owners:
| To move the display: | Use this key: |
|---|---|
| Up by one owner | ↑ |
| Down by one owner | ↓ |
| Up by one page (horizontal scrollbar thumb size) | Page Up |
| Down by one page (horizontal scrollbar thumb size) | Page Down |
| To the top of the owner list | Home |
| To the bottom of the owner list | End |
When you pause your mouse pointer over an owner or an event, you'll see relevant information (e.g. PID, timestamps, etc.).
Just as you can bookmark lines in a text file, in the System Profiler editor, you can bookmark particular locations and event ranges displayed, and then see your bookmarked events in the Bookmarks view.
The Client/Server CPU Statistics view () tracks the amount of client/server time spent in the RUNNING state. In a message-passing system, it may be that a particular thread is consuming a large amount of CPU time, but that CPU time is being consumed based on requests from one or more clients. In these cases, in order to achieve a higher performance, the client requests on the server must be reduced (assuming that the server is identified as a bottleneck).
This panel provides a tabular display of threads that spend time in a RUNNING state (slightly different from pure CPU usage) and breaks down the display such that for each thread there is a summary of how much time it spent directly in the RUNNING state and how much RUNNING time it “imposed” on other threads in the system and the total of those two times.
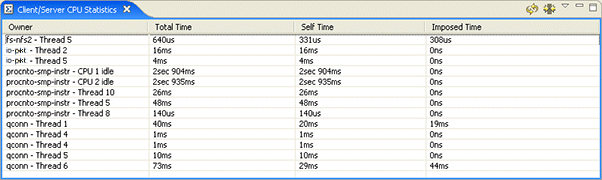
The System Profiler's Client/Server CPU Statistics view.
You can expand the table, via the View menu, to show how much time the client imposed on various server threads. The imposed time is cumulative: if client A sends to server B, then until B replies to A, any time that B consumes is seen as “imposed on” time. If during that time B sends to server C, then server C is also billed time as “imposed on” by A. The rationale here is that B would not have engaged with server C were it not for the initial message from A.
By sorting by imposed time, it is possible to identify which clients are predominantly driving the system and which servers may be bottleneck points.
This view provides a tabular statistical representation of particular events. The statistics can be gathered for the entire log file or for a selected range.
When you first open the Condition Statistics view, it contains no data:
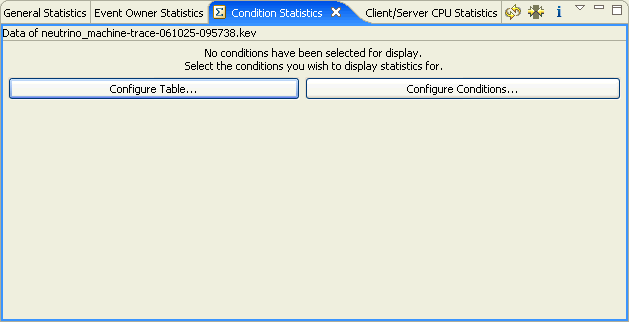
You must configure conditions and the table to view condition statistics.
To configure conditions for the Condition Statistics view:
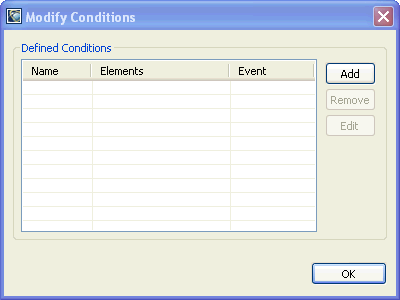
The IDE displays the Condition Selection dialog:
|
You'll need to click the Refresh button
( |
The CPU Migration pane provides a display that draws attention to some of the potential performance problems that are associated with multiple-CPU systems.
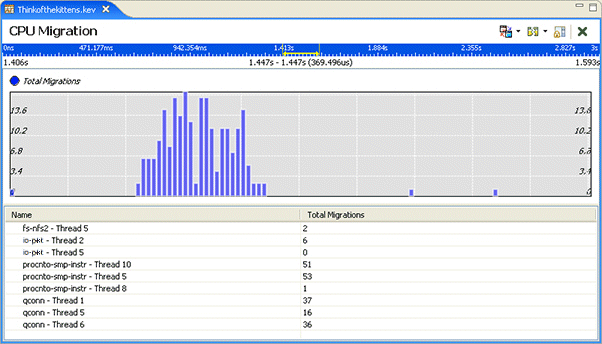
The System Profiler's CPU Migration pane.
There are two migration details that are currently charted over the period of the log file:
This pane contains valid data only when the log file contains events from a system where there are multiple CPUs.
This view provides a tabular statistical representation of particular events. The statistics are organized and detailed by event owner.
|
You'll need to click the Refresh button ( |
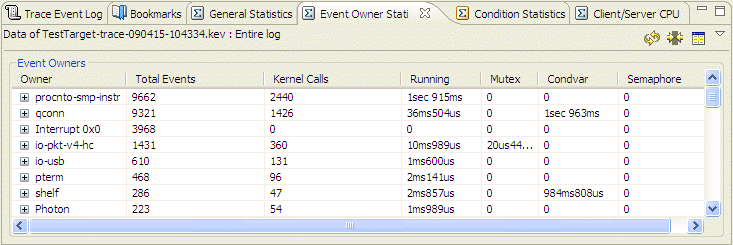
This view provides a tabular statistical representation of particular events, and statistics regarding states. The statistics can be gathered for the entire log file or for a selected range.
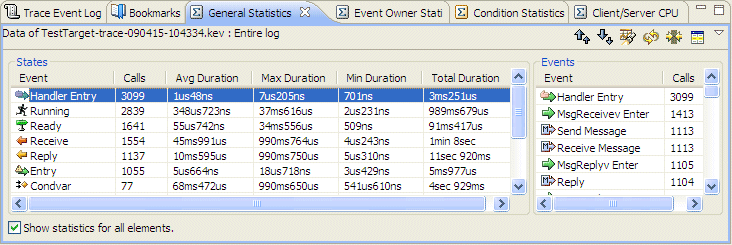
|
You'll need to click the Refresh button ( |
The Raw Event Data view () lets you examine the data payload of a particular selected event. It shows a table of event data keys and their values. For example if an event is selected in the Trace Log view, rather than attempting to look at all of the data in the single line entry, you can open the Raw Event Data view to display the data details more effectively.
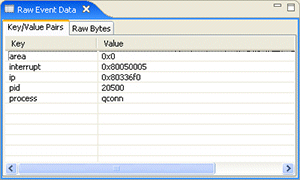
The System Profiler's Raw Event Data view.
The Overview view () shows two charts spanning the entire log file range.
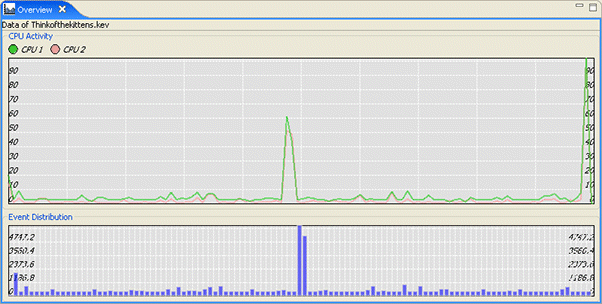
The System Profiler's Overview view.
These charts display the CPU usage (per CPU) over time and the volume of events over time. The Overview reflects the current state of the active editor and active editor pane. You can select an area of interest in either one of the charts; then, using the right-click menu, zoom in to display only that range of events to quickly isolate areas of interest due to abnormal system activity.
The Partition Summary pane provides a summary of the entire log file, focused on QNX's adaptive partitioning technology. For each distinct configuration of partitions detected in the log file, the distribution of CPU usage used by those partitions is displayed, along with a tabular display showing the distribution of CPU usage per event owner per partition.
You can use this information in conjunction with the CPU Usage editor pane to drill down into areas of interest. This pane contains valid data only when the log file contains partition information, and the process and thread states are logged in wide mode (so the partition thread scheduling information is collected).
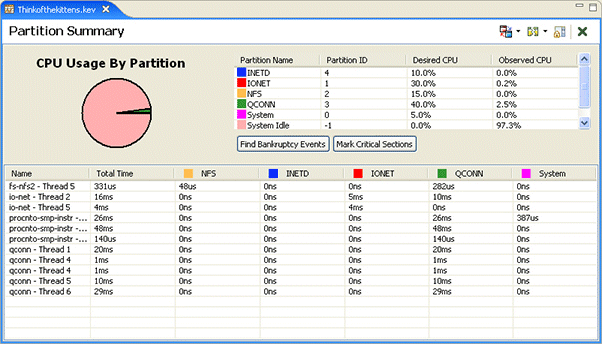
The System Profiler's Partition Summary pane.
You can also get snapshots of the usage of the adaptive partitioning on your system through the System Information perspective's Partition Summary view. For more information, see the Getting System Information chapter.
Notice that this pane displays its summary information based on a time range selection specified in the Timeline pane. At the bottom of the pane, the Status Bar indicates for which time range the data is being presented. By default, you'll see partition information for the full event log range; however, you can use the toggle button in the toolbar of the pane to indicate that you want the information filtered for a specified range.
|
Since the calculations in the Partition Summary pane are intensive, you'll need to use the Refresh button to update the statistics each time you change the toggle, or adjust the range in the Timeline pane. |
In addition to asking why a particular process's thread may be running, developers are often faced with the task of understanding what the rest of the system is doing at a particular point in time. This question can easily be answered using the Thread State Snapshot view ().
Thread State Snapshot view, is keyed off of the current cursor position in the System Profiler editor Timeline pane. For a given time/position, it determines the state of all of the threads in the system.
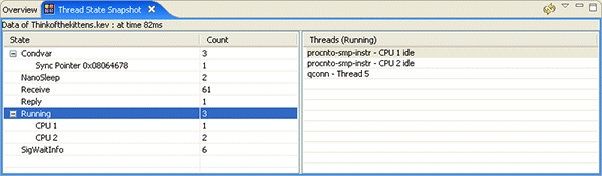
The System Profiler's Thread State Snapshot view.
Note that when you select a point in the Timeline, you must click the Refresh icon in the Thread State Snapshot view's toolbar to update the contents of the Thread State Snapshot view .
You can use the Timeline State Colors view () if you're unfamiliar with the System Profiler timeline editor pane state colorings, or if you'd like to change the color settings to something more appropriate for your task.
The view displays a table with all of the color and height markers that are used when drawing the timeline display. These settings can be bulk imported and exported using the view's dropdown menu based on particular task requirements. The default settings generally categorize states with similar activities together (synchronization, waiting, scheduling, etc.).
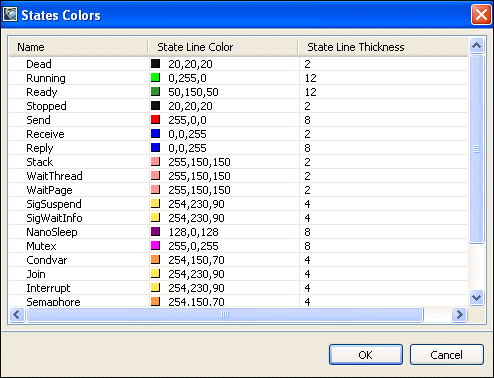
The System Profiler's Timeline State Colors view.
This view can display additional details for the events surrounding the cursor in the editor. The additional detail includes the event number, time, class, and type, as well as decoding the data associated with a particular event.
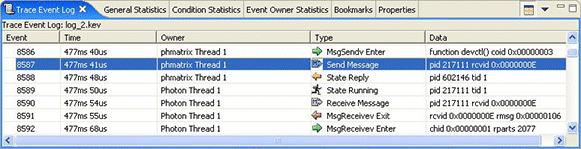
To set the format for event data, select , expand QNX, and then select User Events Data.
The following is an example of an event configuration file that has been documented to describe it's contents:
<?xml version="1.0" encoding="UTF-8" ?>
<!--
Root tag for the event definition file format
-->
<eventdefinitions>
<!--
Events definitions are broken down by the event class.
The user event class is '6' (from <trace.h>); all event codes
in this section are part of this event class.
-->
<eventclass id="6" name="User Events"<
<!--
The user event we want to describe is coded as event #12 within
the user event class (6). It is composed of a single 4 byte
(32 bit) unsigned integer that is followed by a null terminated
string. In C the structure might look something like:
struct event_twelve {
uint32_t myvalue;
char mystring[28]; /* Null Terminated */
};
And be emitted using code:
stuct event_twelve event;
... /* Fill event */
TraceEvent(_NTO_TRACE_INSERTCUSEREVENT, 12, &event, sizeof(event));
-->
<event id="12" sformat="%4u1x myvalue %1s0 mystring" />
<!--
In general an event is described as a serial series of event
payload definitions:
%<size><signed><count><format> <label>
Where:
<size>
Is the size in bytes (1,2,4,8)
<signed>
Is the signed/unsigned attribute of the value (s,u)
<count>
Is the number of items to read (ie an array). There is a
special case where if the <size> is 1 and there is _NO_
format then the <count> can be 0 to accomodate NULL
terminated strings.
<format> (optional)
Is a hint as to how to format this value: d=decimal,
x=hexadecimal, o=octal, c=character
<label>
Is a string label that can't contain the % character
-->
</eventclass>
</eventdefinitions>
The Why Running? view () works in conjunction with the System Profiler timeline editor pane to provide developers with a single click to answer the question “Why is this thread running?” where “this thread” is the actively executing thread at the current cursor position.
By repeating this action (or generating the entire running backtrace) developers can get a clearer view of the sequence of activities leading up to their original execution position. Not to be confused with an execution backtrace, this “running backtrace” highlights the cause/effect relationship leading up to the initial execution position.
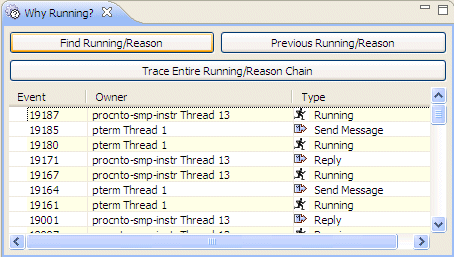
The System Profiler's Why Running? view.
This section describes some cases where you'd use the System Profiler:
You might want to know where in time your CPU cycles are being consumed and who is doing the consuming. The System Profiler provides several tools to help extract this information and “drill down” to quickly and easily determine the source and distribution of CPU consumption.
To extract CPU usage metrics using the System Profiler tools, the captured log file must contain at a minimum, the Neutrino RUNNING thread state. If the RUNNING thread state is logged in wide mode, then additional information regarding CPU usage distribution over priority and partitions can also be calculated.
In order to determine the CPU load caused by interrupts, you must also log the Interrupt Entry/Exit events.
To start, open the target log file in the System Profiler editor. By default, the initial view should show the Summary editor pane; if this isn't the case, then you can get to the Summary editor pane via the menu item .
The Summary editor pane shows a high-level overview of the log file contents:
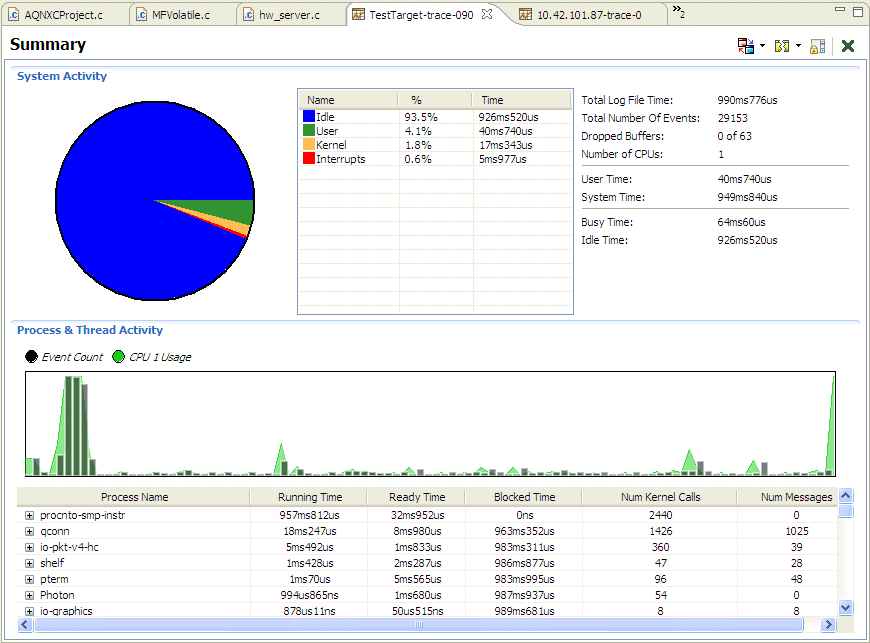
The System Activity section shows the distribution of time spent in the log file, separated into these categories:
Using these metrics, you can get a rough estimate of how efficiently your system is performing (e.g. amount of idle time, ratio of system to user time, possible interrupt flooding).
The distribution of CPU usage over the time of the entire log file is shown graphically in the Process & Thread Activity section overlaid with the volume of events that have been generated. This same data is also available as the Overview view accessed via .
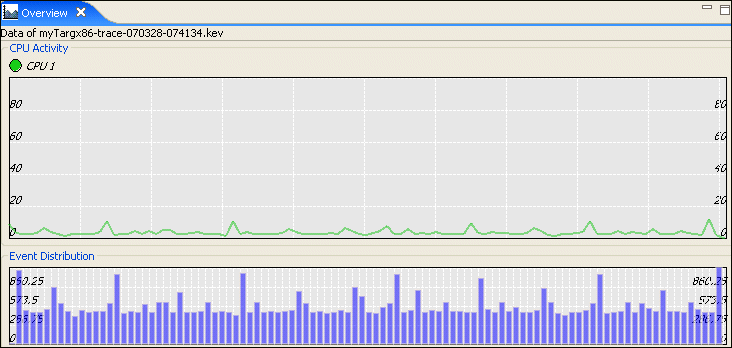
The peaks of these results indicate areas of particularly intense CPU usage and are the areas of most interest.
To focus on the particular threads that are causing these spikes, switch the editor display pane to the CPU Usage editor pane. You can do this via the menu item or by using the editor pull down.
The CPU Usage editor display charts the CPU usage of consuming elements (threads and interrupts) over time and provides a tabular view showing the sum of this usage categorized by CPU, priority, or partition.
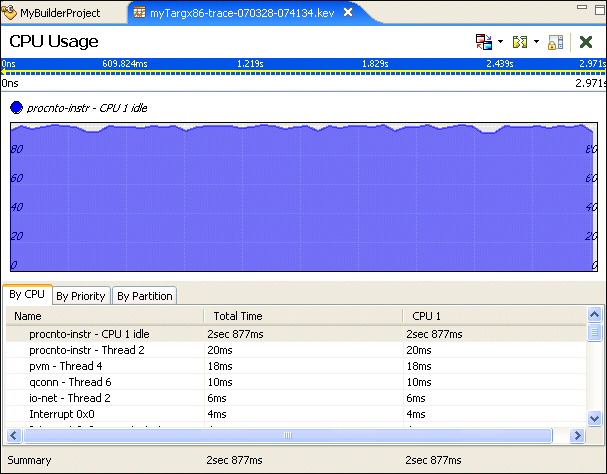
By selecting multiple elements in the table, you can “stack” the CPU usage to see how threads and interrupts are interacting. For example, selecting the first few non-idle CPU consumers in this example provides the following result:
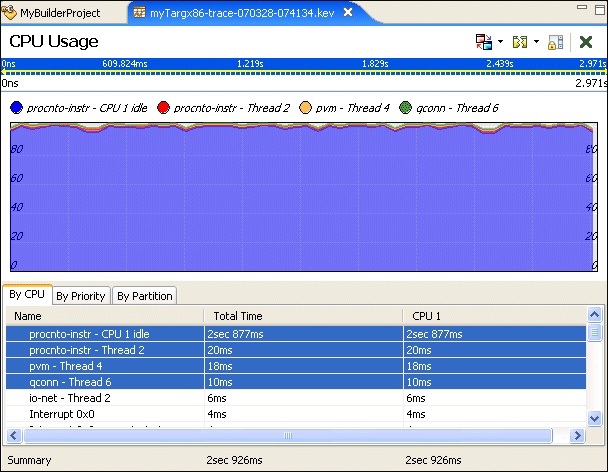
By selecting a region of the display, you can zoom in to the area of interest to further drill down into selected areas to better examine the profile of the CPU execution. As the display zooms in, the editor panel's time bar is updated to show the new range of time being examined.
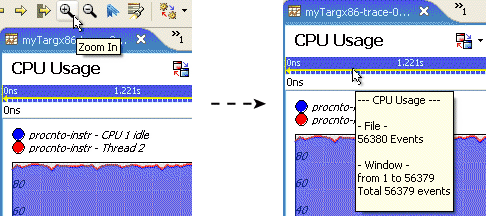
This example has shown the CPU usage for process threads, but this technique applies equally well to individual interrupt handlers, which show up as CPU consumers in the same manner as threads.
The CPU Usage editor pane lets you isolate and assign CPU consumption behavior to specific threads very quickly and easily. With this information, you can generally use a more specialized, and application centric, tool such as the Application Profiler to look more closely at execution behavior and to drill down directly to the application source code.
There are many cases where high CPU load is traced back to server activity. However, in most cases what is required to reduce this CPU load isn't to make the servers more efficient, but to look more closely at the client activity that is causing the servers to run.
|
Make sure you've read and understood “Locating sources of high CPU usage” before examining this use case. |
In addition to the Neutrino RUNNING thread state, the log must contain the communication events SEND/RECEIVE/REPLY|ERROR. These communication events are used to establish the relationship between clients and servers.
QNX Neutrino systems rely heavily on client/server communications most often performed via message passing. In these systems, clients send requests to servers asking them to do work on their behalf such as shown:
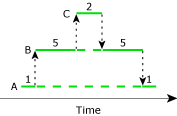
Here, A's real CPU usage would be considered to be 2 units of time, B's as 10, and C's as 2 units of time. Since B and C are both acting as servers, they really execute only when there are clients generating requests for action. Most standard CPU Usage metrics don't take this type of “on behalf of” work into consideration. However, if the goal of a kernel log file investigation is to locate the source or sources of CPU load, then this type of metric is invaluable in assigning “blame” for high CPU usage.
The System Profiler provides the Client/Server CPU Statistics view to help extract this type of “on behalf of” metric. You can activate this view via the .
Once activated, the Client/Server CPU Statistics are gathered on demand, by default, targeting the full range of the target log file:
The default display of this view shows the simplified view that displays the RUNNING time (slightly different from the CPU Usage in that it doesn't remove the time spent interrupted by interrupt handlers) that CPU consumers are consuming directly, indirectly, and summed together as a total:
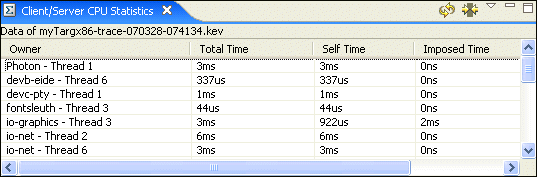
In this case, it's clear that while the qconn- Thread 1 isn't consuming much CPU on its own, it's imposing a significant amount of time on the system indirectly. If you compare this data to what the CPU Usage editor pane displays, you'll see the difference in what's reported:
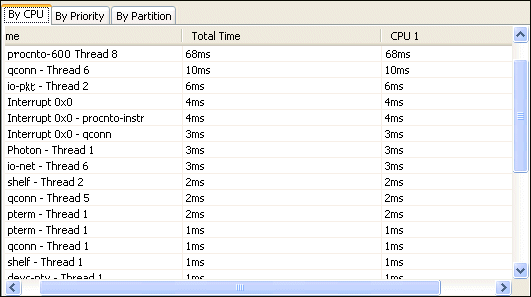
In the CPU Usage table, procnto- Thread 8 ranks ahead of qconn- Thread 1 in its usage. However, procnto is a pure server process, so we know that it consumes no CPU resources without being solicited to do so. We suspect that perhaps qconn- Thread 1 is driving procnto- Thread 1.
We can confirm this suspicion by looking at which servers qconn- Thread 1 is imposing CPU usage on. You can configure the Client/Server CPU Usage view to display all of the CPU consumers that are being imposed on (and by whom) by selecting Show all times from the view's dropdown menu:
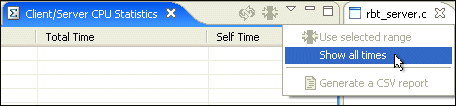
The Client/Server CPU Usage view table changes to show all of the imposed-on servers that clients are communicating with. The servers are listed in the columns and the clients in the Owner column. Note that this may result in a table with many columns (imposed on servers):
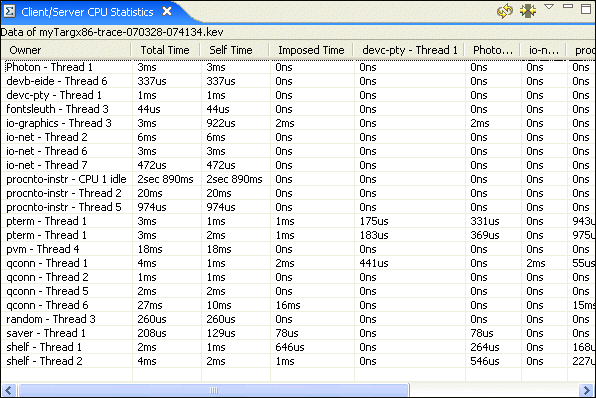
Here we can see that in fact nearly all of the time that procnto- Thread 8 is spending consuming CPU is due to requests coming from qconn- Thread 1, with only a minimal amount being imposed on it by another qconn thread, qconn- Thread 6.
This is to be expected, since in order to query the system, the qconn process must communicate with the kernel to extract the system state and all the process and thread information.
There are several different types of interrupt latency that you can measure in a system:
The System Profiler, as a type of software logic analyzer, helps you look at the timing of activities once the interrupt has been acknowledged by the operating system. In order to accurately measure the time between the signal generation and the acknowledgment of it, you need additional hardware tools.
To measure interrupt service time (the time taken for the operating system to acknowledge the interrupt, handle it, and return to normal processing), you must log the Neutrino Interrupt Entry/Exit events.
If you're interested in the time from the operating system's acknowledgment to a service handling routine, then you also need to capture the Interrupt Handler Entry/Exit events in the log file.
To properly gauge the latency in triggering a response in user code, you should also log the Neutrino thread READY and RUNNING states, in addition to the communication PULSE events, since these are often used to trigger a user application's behavior in response to an interrupt.
Interrupt activity is best viewed in the System Profiler editor using the Timeline editor pane. Open the target log file in the System Profiler editor. Switch to the Timeline editor pane via the menu item .
You should see a display that resembles the following. The details will of course be different, but the layout similar:
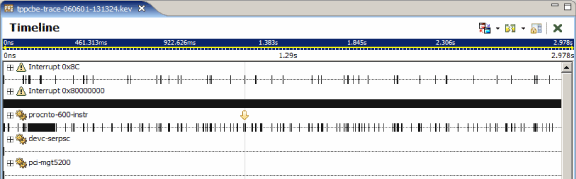
This display shows the various event owners/sources (interrupts, interrupt handlers, processes and threads) as a tree with their associated events arranged horizontally as a timeline.
If you've logged Interrupt Handler Entry/Exit events, then you should be able to expand the interrupt entries to show the various handlers (more than one handler can be attached to service an interrupt source), such as the following:
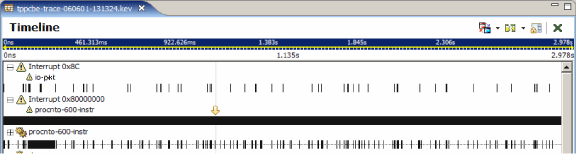
Here you can see that the io-pkt process has attached to Interrupt 0x8c and that procnto has attached to Interrupt 0x800000000, which on this system is the timer interrupt firing once every millisecond or so.
You can determine how many interrupt events are occurring in this log file by using the General Statistics view. This view is part of the default System Profiler perspective, and you can also access it via .

If you use the refresh button, this view extracts the event statistics for the entire log file (default), or for only a selected area if specified. This results in the following display:
This table provides a breakdown for all of the event sources, showing the number of raw events and also the maximum, minimum, average, and total duration of the various Neutrino thread states in this log file.
If you're interested in only the events associated with the timer interrupt (Interrupt 0x80000000), you can select that event owner in the Timeline editor pane:
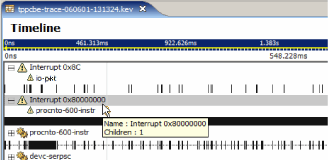
Next, uncheck the Show statistics for all elements check box at the bottom of the General Statistics view:
The General Statistics view tables will show the content limited to just the selected event owners.
Using this technique, you can get an estimate of the rough order of magnitude of how many events you're looking at in a log file, and in the case of interrupts, you can see some of the statistics about what the maximum, minimum, average, and total times spent were.
This display also lets you drill down further into the results, by allowing navigation in the Timeline editor pane directly to the maximum and minimum times, where you can look at the exact timing sequences. To do this, select one of the entries in the States table, and then right-click or use the toolbar to jump to the appropriate selection.
In order to look at the timing sequence of an interrupt, you usually have to zoom in on the timeline a significant amount to achieve an adequate level of visual detail, since interrupt processing is typically fast compared to the length of the log files. If you zoom into an area where a networking interrupt is being processed, the Timeline editor pane will change to look something like:
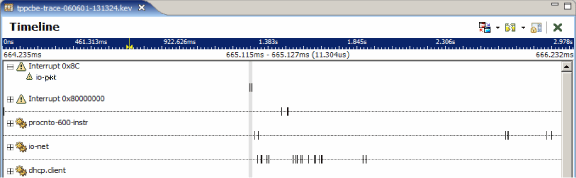
At this level of granularity, it also helps to see the trace event log concurrently with the Timeline editor pane. This is part of the standard System Profiler perspective, and you can access it using . The Trace Event Log and the Timeline editor pane are synchronized; when you change your cursor in the editor, the selection in the Trace Event Log view also changes.
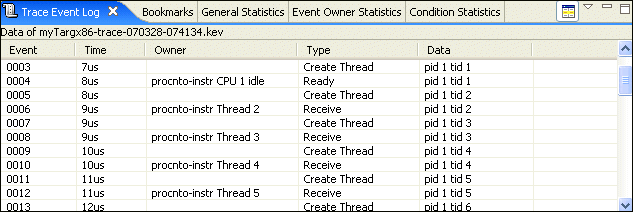
The selection synchronization is shown here. In the Trace Event Log view, we've selected the Interrupt 0x8c Entry event through to the Interrupt 0x8c Exit event. This represents the start to end of the processing of the interrupt event. In the timeline display, this selection is made and the timing measurement of 11.304 microseconds is displayed:
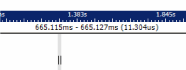
So the total interrupt handling time from start to end of the operating system interrupt service routine, including the event handler was 11.304 microseconds. If you want to just look at the handling time for interrupt handler attached by the io-pkt process, you can see that this time is only 8 microseconds. These times represent the earliest and latest points in time that can be measured before entering/exiting control of the software.
You can also see in this example that the io-pkt interrupt handler is returning a pulse that's triggering something in the user's application (event 13515) and that an io-pkt thread is then scheduled to service that request. You can also measure this latency to determine how long it takes to go from operating system awareness of the interrupt to eventual application processing, using the same selection technique:

There are many different choices in terms of what time ranges are of interest to measure. Here we've decided to measure from the time that the operating system is aware of the interrupt (event 13511) through to the point at which the user process has started to respond to the signal generated by the io-pkt interrupt handler. Since the interrupt handler communicates using a pulse (event 13515), then the earliest that the user code can respond is when the MsgReceive() kernel call exits (event 13519) with the received pulse. In this case, we can see that the end-to-end latency from OS awareness to the start of user processing (nonprivileged) is 46.304 microseconds:
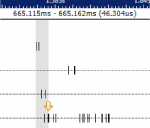
Alternate measurements that could be of interest and that you can easily examine include:
Trace event log files contain a wealth of information, but unfortunately that information is often buried deep in among thousands, if not millions, of other events. The System Profiler tooling helps provide tools to reduce and remove some of this “noise” to help you focus on the areas of a log that are important to you.
There are no specific requirements for this use case, but some of the topics may not apply, depending on the types of events that have been captured.
We'll walk through some of the tools available to help you to reduce and filter the data contained in a trace event file. Where this information is most useful is during investigations involving the Timeline editor pane. The timeline displays information with a very fine granularity and is often the display that users turn to in order to “single step” through the execution flow of an activity of interest. To open the Timeline editor pane, select .
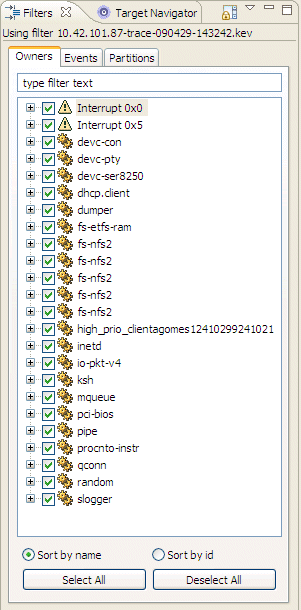
The first level of data reduction is to use the Filters view to remove information that isn't significant for the tracing of the problem you're interested in. By using filters in conjunction with zooming and searching capabilities, you can quickly reduce the overall data set.
The Filters view is synchronized with the active System Profiler editor; you can display it via the menu or by right-clicking Filters… in the Timeline editor pane.
This view provides you with the following types of filtering:
Select the context menu in the Filters view to access additional filter options. Select Configure Filters… from the Filters view menu to configure the filters for System Profiler.
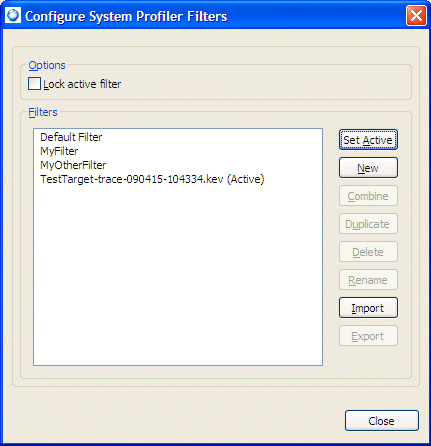
Configuring filters for System Profiler.
The Configure System Profiler Filters dialog provides a listing of preconfigured filters that are available for use. These filters are often based on more sophisticated criteria for determining if events, event owners, or partitions are to be displayed.
By default, the Trace Event Log view presents a display that uses the same filters as the currently active editor. However, there are times when it's useful to be able to temporarily “unfilter” the Trace Event Log view display to see the raw content of the log file. You can accomplish this by toggling the editor's Synchronize button on the Trace Event Log view display:

There are times when you're looking at an event stream and want to quickly navigate through it. One mechanism for doing this is to move to the next or previous event, using the toolbar commands (Next, Previous, Next Event In Selection, Previous Event In Selection).
Another, more flexible, alternative is to use the Find functionality of the Timeline editor pane. Selecting opens a dialog similar to the one found in many text editors:
The dialog supports searching a restricted set of event owners (based on the selection made in the Timeline editor pane) as well as searching forwards and backwards through the log file. This is convenient when you know specifically what type of event you're looking for in a sequence of events (e.g. the next RUNNING state for a thread).
The Find dialog moves the selection marker in the Timeline editor pane to the appropriate event.
If you need to generate a collection of events matching a particular condition, or you need to construct a more complicated expression (perhaps including event data) in order to find the events you're looking for, you need the power of trace event conditions and the Trace Search tool.
The Trace Search tool is invoked via the menu item . Opening this up presents a dialog similar to the following:
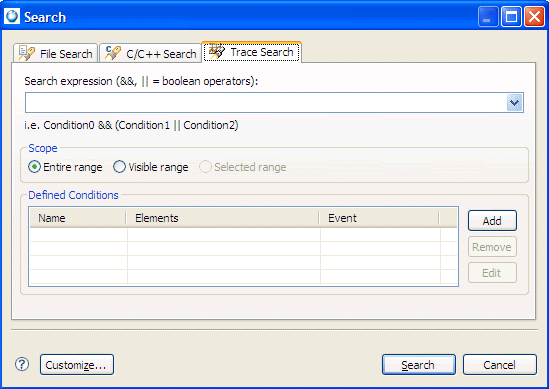
Searching is based on trace conditions. Trace conditions describe a selection criterion for matching an event and can be based on anything that an event provides (ownership, data payload, and so on).
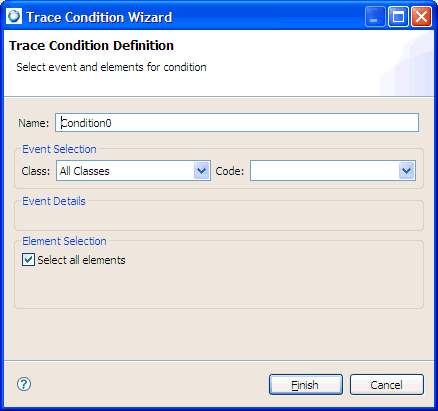
To add a condition that will locate all of the MsgSend() calls that may have been made for write system calls:
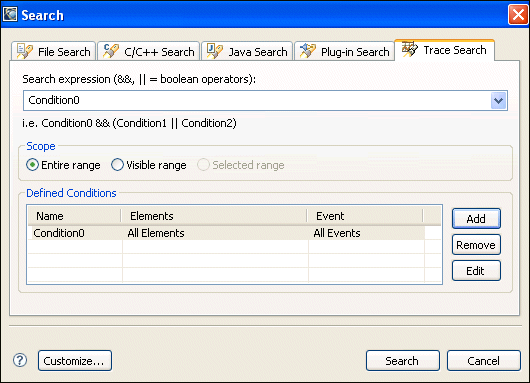
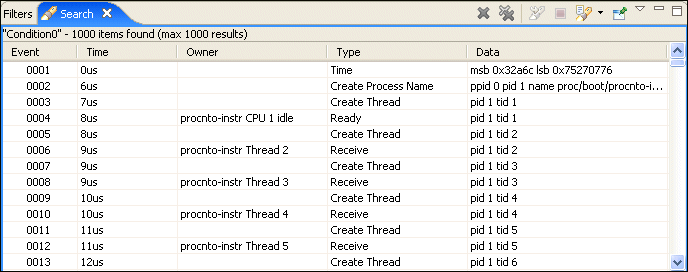
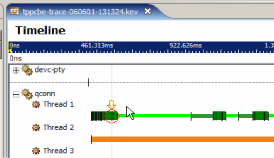
Search results are also marked in the timeline to help show the event distribution over the period of the log file:
Often the kernel event files that are captured are large and contain a significant amount of nonessential data for the problem at hand. Of course, this is generally only determined after the fact, once you've performed some basic analysis.
You can use the menu command to create a new log file that's based on the current log file in the System Profiler editor.
You can restrict the new log file to just the selected area (if you've made a selection), and you can also use the current filter settings (event and event owner) to reduce the amount of additional data that's stored in the log file.
The new log file contains the same attribute information as the original log file (including the system version, system boot time, number of CPUs, and so on). Any event owners, such as interrupts, processes, and threads, which are referenced by events in the new log file, are synthetically created with timestamps matching the start time(s) of the new log file.
|
|
|
|