![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
The key to handling hardware events in a timely manner is for the hardware to generate an interrupt. An interrupt is simply a pause in, or interruption of, whatever the processor was doing, along with a request to do something else.
The hardware generates an interrupt whenever it has reached some state where software intervention is desired. Instead of having the software continually poll the hardware — which wastes CPU time — an interrupt is the preferred method of “finding out” that the hardware requires some kind of service. The software that handles the interrupt is therefore typically called an Interrupt Service Routine (ISR).
Although crucial in a realtime system, interrupt handling has unfortunately been a very difficult and awkward task in many traditional operating systems. Not so with Neutrino. As you'll see in this chapter, handling interrupts is almost trivial; given the fast context-switch times in Neutrino, most if not all of the “work” (usually done by the ISR) is actually done by a thread.
Let's take a look at the Neutrino interrupt functions and at some ways of dealing with interrupts. For a different look at interrupts, see the Interrupts chapter of Getting Started with QNX Neutrino.
On a multicore system, each interrupt is directed to one (and only one) CPU, although it doesn't matter which. How this happens is under control of the programmable interrupt controller chip(s) on the board. When you initialize the PICs in your system's startup, you can program them to deliver the interrupts to whichever CPU you want to; on some PICs you can even get the interrupt to rotate between the CPUs each time it goes off.
For the startups we write, we typically program things so that all interrupts (aside from the one(s) used for interprocessor interrupts) are sent to CPU 0. This lets us use the same startup for both procnto and procnto-smp. According to a study that Sun did a number of years ago, it's more efficient to direct all interrupts to one CPU, since you get better cache utilization.
For more information, see the Customizing Image Startup Programs chapter of Building Embedded Systems.
An ISR (Interrupt Service Routine) that's added by InterruptAttach() runs on the CPU that takes the interrupt.
An IST (Interrupt Service Thread) that receives the event set up by InterruptAttachEvent() runs on any CPU, limited only by the scheduler and the runmask.
A thread that calls InterruptWait() runs on any CPU, limited only by the scheduler and the runmask.
In order to install an ISR, the software must tell the OS that it wishes to associate the ISR with a particular source of interrupts, which can be a hardware Interrupt Request line (IRQ) or one of several software interrupts. The actual number of interrupts depends on the hardware configuration supplied by the board's manufacturer. For the interrupt assignments for specific boards, see the sample build files in ${QNX_TARGET}/${PROCESSOR}/boot/build.
In any case, a thread specifies which interrupt source it wants to associate with which ISR, using the InterruptAttach() or InterruptAttachEvent() function calls; when the software wishes to dissociate the ISR from the interrupt source, it can call InterruptDetach(). For example:
#define IRQ3 3 /* A forward reference for the handler */ extern const sigevent *serint (void *, int); … /* * Associate the interrupt handler, serint, * with IRQ 3, the 2nd PC serial port */ ThreadCtl( _NTO_TCTL_IO, 0 ); id = InterruptAttach (IRQ3, serint, NULL, 0, 0); … /* Perform some processing. */ … /* Done; detach the interrupt source. */ InterruptDetach (id);
 |
The startup code is responsible for making sure that all interrupt sources are masked during system initialization. When the first call to InterruptAttach() or InterruptAttachEvent() is done for an interrupt vector, the kernel unmasks it. Similarly, when the last InterruptDetach() is done for an interrupt vector, the kernel remasks the level. |
Because the interrupt handler can potentially gain control of the machine, we don't let just anybody associate an interrupt. The thread must have I/O privileges — the privileges associated with being able to manipulate hardware I/O ports and affect the processor interrupt enable flag (the x86 processor instructions in, ins, out, outs, cli, and sti). Since currently only the root account can gain I/O privileges, this effectively limits the association of interrupt sources with ISR code.
Let's now take a look at the ISR itself.
In our example above, the function serint() is the ISR. In general, an ISR is responsible for:
Depending on the complexity of the hardware device, the ISR, and the application, some of the above steps may be omitted.
Let's take a look at these steps in turn.
Depending on your hardware configuration, there may actually be multiple hardware sources associated with an interrupt. This issue is a function of your specific hardware and bus type. This characteristic (plus good programming style) mandates that your ISR ensure that the hardware associated with it actually caused the interrupt.
Most PIC (Programmable Interrupt Controller) chips can be programmed to respond to interrupts in either an edge-sensitive or level-sensitive manner. Depending on this programming, interrupts may be sharable.
For example:
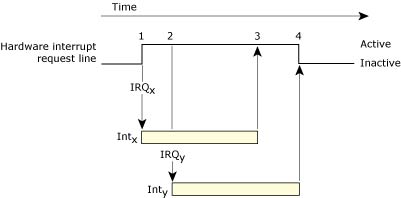
Interrupt request assertion with multiple interrupt sources.
In the above scenario, if the PIC is operating in a level-sensitive mode, the IRQ is considered active whenever it's high. In this configuration, while the second assertion (step 2) doesn't itself cause a new interrupt, the interrupt is still considered active even when the original cause of the interrupt is removed (step 3). Not until the last assertion is cleared (step 4) will the interrupt be considered inactive.
In edge-triggered mode, the interrupt is “noticed” only once, at step 1. Only when the interrupt line is cleared, and then reasserted, does the PIC consider another interrupt to have occurred.
Neutrino allows ISR handlers to be stacked, meaning that multiple ISRs can be associated with one particular IRQ. The impact of this is that each handler in the chain must look at its associated hardware and determine if it caused the interrupt. This works reliably in a level-sensitive environment, but not an edge-triggered environment.
To illustrate this, consider the case where two hardware devices are sharing an interrupt. We'll call these devices “HW-A” and “HW-B.” Two ISR routines are attached to one interrupt source (via the InterruptAttach() or InterruptAttachEvent() call), in sequence (i.e. ISR-A is attached first in the chain, ISR-B second).
Now, suppose HW-B asserts the interrupt line first. Neutrino detects the interrupt and dispatches the two handlers in order — ISR-A runs first and decides (correctly) that its hardware did not cause the interrupt. Then ISR-B runs and decides (correctly) that its hardware did cause the interrupt; it then starts servicing the interrupt. But before ISR-B clears the source of the interrupt, suppose HW-A asserts an interrupt; what happens depends on the type of IRQ.
If you have an edge-triggered bus, when ISR-B clears the source of the interrupt, the IRQ line is still held active (by HW-A). But because it's edge-triggered, the PIC is waiting for the next clear/assert transition before it decides that another interrupt has occurred. Since ISR-A already ran, it can't possibly run again to actually clear the source of the interrupt. The result is a “hung” system, because the interrupt will never transit between clear and asserted again, so no further interrupts on that IRQ line will ever be recognized.
On a level-sensitive bus, when ISR-B clears the source of the interrupt, the IRQ line is still held active (by HW-A). When ISR-B finishes running and Neutrino sends an EOI (End Of Interrupt) command to the PIC, the PIC immediately reinterrupts the kernel, causing ISR-A (and then ISR-B) to run.
Since ISR-A clears the source of the interrupt (and ISR-B doesn't do anything, because its associated hardware doesn't require servicing), everything functions as expected.
The above discussion may lead you to the conclusion that “level-sensitive is good; edge-triggered is bad.” However, another issue comes into play.
In a level-sensitive environment, your ISR must clear the source of the interrupt (or at least mask it via InterruptMask()) before it completes. (If it didn't, then when the kernel issued the EOI to the PIC, the PIC would then immediately reissue a processor interrupt and the kernel would loop forever, continually calling your ISR code.)
In an edge-triggered environment, there's no such requirement, because the interrupt won't be noticed again until it transits from clear to asserted.
In general, to actually service the interrupt, your ISR has to do very little; the minimum it can get away with is to clear the source of the interrupt and then schedule a thread to actually do the work of handling the interrupt. This is the recommended approach, for a number of reasons:
|
Since the range of hardware attached to an interrupt source can be very diverse, the specific how-to's of servicing the interrupt are beyond the scope of this document — this really depends on what your hardware requires you to do. |
When the ISR is servicing the interrupt, it can't make any kernel calls (except for the few that we'll talk about shortly). This means that you need to be careful about the library functions that you call in an ISR, because their underlying implementation may use kernel calls.
|
For a list of the functions that you can call from an ISR, see the Summary of Safety Information appendix in the Library Reference. |
Here are the only kernel calls that the ISR can use:
You'll also find these functions (which aren't kernel calls) useful in an ISR:
Let's look at these functions.
To prevent a thread and ISR from interfering with each other, you'll need to tell the kernel to disable interrupts. On a single-processor system, you can simply disable interrupts using the processor's “disable interrupts” opcode. But on an SMP system, disabling interrupts on one processor doesn't disable them on another processor.
The function InterruptDisable() (and the reverse, InterruptEnable()) performs this operation on a single-processor system. The function InterruptLock() (and the reverse, InterruptUnlock()) performs this operation on an SMP system.
|
We recommend that you always use the SMP versions of these functions — this makes your code portable to SMP systems, with a negligible amount of overhead. |
The InterruptMask() and InterruptUnmask() functions disable and enable the PIC's recognition of a particular hardware IRQ line. These calls are useful if your interrupt handler ISR is provided by the kernel via InterruptAttachEvent() or if you can't clear the cause of the interrupt in a level-sensitive environment quickly. (This would typically be the case if clearing the source of the interrupt is time-consuming — you don't want to spend a lot of time in the interrupt handler. The classic example of this is a floppy-disk controller, where clearing the source of the interrupt may take many milliseconds.) In this case, the ISR would call InterruptMask() and schedule a thread to do the actual work. The thread would call InterruptUnmask() when it had cleared the source of the interrupt.
Note that these two functions are counting — InterruptUnmask() must be called the same number of times as InterruptMask() in order to have the interrupt source considered enabled again.
The TraceEvent() function traces kernel events; you can call it, with some restrictions, in an interrupt handler. For more information, see the System Analysis Toolkit User's Guide.
Another issue that arises when using interrupts is how to safely update data structures in use between the ISR and the threads in the application. Two important characteristics are worth repeating:
This means that you can't use thread-level synchronization (such as mutexes, condvars, etc.) in an ISR.
Because the ISR runs at a higher priority than any software thread, it's up to the thread to protect itself against any preemption caused by the ISR. Therefore, the thread should issue InterruptDisable() and InterruptEnable() calls around any critical data-manipulation operations. Since these calls effectively turn off interrupts, the thread should keep the data-manipulation operations to a bare minimum.
With SMP, there's an additional consideration: one processor could be running the ISR, and another processor could be running a thread related to the ISR. Therefore, on an SMP system, you must use the InterruptLock() and InterruptUnlock() functions instead. Again, using these functions on a non-SMP system is safe; they'll work just like InterruptDisable() and InterruptEnable(), albeit with an insignificantly small performance penalty.
Another solution that can be used in some cases to at least guarantee atomic accesses to data elements is to use the atomic_*() function calls (below).
Since the environment the ISR operates in is very limited, generally you'll want to perform most (if not all) of your actual “servicing” operations at the thread level.
At this point, you have two choices:
This is effectively the difference between InterruptAttach() (where an ISR is attached to the IRQ) and InterruptAttachEvent() (where a struct sigevent is bound to the IRQ).
Let's take a look at the prototype for an ISR function and the InterruptAttach() and InterruptAttachEvent() functions:
int
InterruptAttach (int intr,
const struct sigevent * (*handler) (void *, int),
const void *area,
int size,
unsigned flags);
int
InterruptAttachEvent (int intr,
const struct sigevent *event,
unsigned flags);
const struct sigevent *
handler (void *area, int id);
Looking at the prototype for InterruptAttach(), the function associates the IRQ vector (intr) with your ISR handler (handler), passing it a communications area (area). The size and flags arguments aren't germane to our discussion here (they're described in the Library Reference for the InterruptAttach() function).
For the ISR, the handler() function takes a void * pointer and an int identification parameter; it returns a const struct sigevent * pointer. The void * area parameter is the value given to the InterruptAttach() function — any value you put in the area parameter to InterruptAttach() is passed to your handler() function. (This is simply a convenient way of coupling the interrupt handler ISR to some data structure. You're certainly free to pass in a NULL value if you wish.)
After it has read some registers from the hardware or done whatever processing is required for servicing, the ISR may or may not decide to schedule a thread to actually do the work. In order to schedule a thread, the ISR simply returns a pointer to a const struct sigevent structure — the kernel looks at the structure and delivers the event to the destination. (See the Library Reference under sigevent for a discussion of event types that can be returned.) If the ISR decides not to schedule a thread, it simply returns a NULL value.
As mentioned in the documentation for sigevent, the event returned can be a signal or a pulse. You may find that a signal or a pulse is satisfactory, especially if you already have a signal or pulse handler for some other reason.
Note, however, that for ISRs we can also return a SIGEV_INTR. This is a special event that really has meaning only for an ISR and its associated controlling thread.
A very simple, elegant, and fast way of servicing interrupts from the thread level is to have a thread dedicated to interrupt processing. The thread attaches the interrupt (via InterruptAttach()) and then the thread blocks, waiting for the ISR to tell it to do something. Blocking is achieved via the InterruptWait() call. This call blocks until the ISR returns a SIGEV_INTR event:
main ()
{
// perform initializations, etc.
…
// start up a thread that is dedicated to interrupt processing
pthread_create (NULL, NULL, int_thread, NULL);
…
// perform other processing, as appropriate
…
}
// this thread is dedicated to handling and managing interrupts
void *
int_thread (void *arg)
{
// enable I/O privilege
ThreadCtl (_NTO_TCTL_IO, NULL);
…
// initialize the hardware, etc.
…
// attach the ISR to IRQ 3
InterruptAttach (IRQ3, isr_handler, NULL, 0, 0);
…
// perhaps boost this thread's priority here
…
// now service the hardware when the ISR says to
while (1)
{
InterruptWait (NULL, NULL);
// at this point, when InterruptWait unblocks,
// the ISR has returned a SIGEV_INTR, indicating
// that some form of work needs to be done.
…
// do the work
…
// if the isr_handler did an InterruptMask, then
// this thread should do an InterruptUnmask to
// allow interrupts from the hardware
}
}
// this is the ISR
const struct sigevent *
isr_handler (void *arg, int id)
{
// look at the hardware to see if it caused the interrupt
// if not, simply return (NULL);
…
// in a level-sensitive environment, clear the cause of
// the interrupt, or at least issue InterruptMask to
// disable the PIC from reinterrupting the kernel
…
// return a pointer to an event structure (preinitialized
// by main) that contains SIGEV_INTR as its notification type.
// This causes the InterruptWait in "int_thread" to unblock.
return (&event);
}
In the above code sample, we see a typical way of handling interrupts. The main thread creates a special interrupt-handling thread (int_thread()). The sole job of that thread is to service the interrupts at the thread level. The interrupt-handling thread attaches an ISR to the interrupt (isr_handler()), and then waits for the ISR to tell it to do something. The ISR informs (unblocks) the thread by returning an event structure with the notification type set to SIGEV_INTR.
This approach has a number of advantages over using an event notification type of SIGEV_SIGNAL or SIGEV_PULSE:
The only caveat to be noted when using InterruptWait() is that the thread that attached the interrupt is the one that must wait for the SIGEV_INTR.
Most of the discussion above for InterruptAttach() applies to the InterruptAttachEvent() function, with the obvious exception of the ISR. You don't provide an ISR in this case — the kernel notes that you called InterruptAttachEvent() and handles the interrupt itself. Since you also bound a struct sigevent to the IRQ, the kernel can now dispatch the event. The major advantage is that we avoid a context switch into the ISR and back.
An important point to note is that the kernel automatically performs an InterruptMask() in the interrupt handler. Therefore, it's up to you to perform an InterruptUnmask() when you actually clear the source of the interrupt in your interrupt-handling thread. This is why InterruptMask() and InterruptUnmask() are counting.
If you're working with interrupts, you might see an Out of Interrupt Events error. This happens when the system is no longer able to run user code and is stuck in the kernel, most frequently because:
Or:
If you call InterruptAttach() in your code, look at the handler code first and make sure you're properly clearing the interrupt condition from the device before returning to the OS.
If you encounter this problem, even with all hardware interrupts disabled, it could be caused by misuse or excessive use of software timers.
It's possible for different devices to share an interrupt (for example if you've run out of hardware interrupt lines), but we don't recommend you do this with hardware that will be generating a lot of interrupts. We also recommend you not share interrupts with drivers that you don't have complete source control over, because you need to be sure that the drivers process interrupts properly.
Sharing interrupts can decrease your performance, because when the interrupt fires, all of the devices sharing the interrupt need to run and check to see if it's for them. Many drivers read the registers in their interrupt handlers to see if the interrupt is really for them, and then ignore it if it isn't. But some drivers don't; they schedule their thread-level event handlers to check their hardware, which is inefficient and reduces performance.
|
If you have a frequent interrupt source sharing an interrupt with a driver that schedules a thread to check the hardware, the overhead of scheduling the thread becomes noticeable. |
Sharing interrupts can increase interrupt latency, depending upon exactly what each of the drivers does. After an interrupt fires, the kernel doesn't reenable it until all driver handlers tell the kernel that they've finished handling it. If one driver takes a long time servicing a shared interrupt that's masked, and another device on the same interrupt causes an interrupt during that time period, the processing of that interrupt can be delayed for an unknown length of time.
Now that we've seen the basics of handling interrupts, let's take a look at some more details and some advanced topics.
When your ISR is running, it runs in the context of the process that attached it, except with a different stack. Since the kernel uses an internal interrupt-handling stack for hardware interrupts, your ISR is impacted in that the internal stack is small. Generally, you can assume that you have about 200 bytes available.
The PIC doesn't get the EOI command until after all ISRs — whether supplied by your code via InterruptAttach() or by the kernel if you use InterruptAttachEvent() — for that particular interrupt have been run. Then the kernel itself issues the EOI; your code should not issue the EOI command.
If you're using interrupt sharing, then by default when you attach an ISR using InterruptAttach() or InterruptAttachEvent(), the new ISR goes to the beginning of the list of ISRs for that interrupt. You can specifically request that your ISR be placed at the end of the list by specifying a flags argument of _NTO_INTR_FLAGS_END.
Note that there's no way to specify any other order (e.g. middle, fifth, second, etc.).
Another factor of concern for realtime systems is the amount of time taken between the generation of the hardware interrupt and the first line of code executed by the ISR. There are two factors to consider here:
Some convenience functions are defined in the include file <atomic.h> — these allow you to perform atomic operations (i.e. operations that are guaranteed to be indivisible or uninterruptible).
Using these functions alleviates the need to disable and enable interrupts around certain small, well-defined operations with variables, such as:
Variables used in an ISR must be marked as “volatile”.
See the Library Reference under atomic_*() for more information.
|
|
|
|