![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
This chapter includes:
Before we start talking about threads, processes, time slices, and all the other wonderful “scheduling concepts,” let's establish an analogy.
What I want to do first is illustrate how threads and processes work. The best way I can think of (short of digging into the design of a realtime system) is to imagine our threads and processes in some kind of situation.
Let's base our analogy for processes and threads using a regular, everyday object — a house.
A house is really a container, with certain attributes (such as the amount of floor space, the number of bedrooms, and so on).
If you look at it that way, the house really doesn't actively do anything on its own — it's a passive object. This is effectively what a process is. We'll explore this shortly.
The people living in the house are the active objects — they're the ones using the various rooms, watching TV, cooking, taking showers, and so on. We'll soon see that's how threads behave.
If you've ever lived on your own, then you know what this is like — you know that you can do anything you want in the house at any time, because there's nobody else in the house. If you want to turn on the stereo, use the washroom, have dinner — whatever — you just go ahead and do it.
Things change dramatically when you add another person into the house. Let's say you get married, so now you have a spouse living there too. You can't just march into the washroom at any given point; you need to check first to make sure your spouse isn't in there!
If you have two responsible adults living in a house, generally you can be reasonably lax about “security” — you know that the other adult will respect your space, won't try to set the kitchen on fire (deliberately!), and so on.
Now, throw a few kids into the mix and suddenly things get a lot more interesting.
Just as a house occupies an area of real estate, a process occupies memory. And just as a house's occupants are free to go into any room they want, a processes' threads all have common access to that memory. If a thread allocates something (mom goes out and buys a game), all the other threads immediately have access to it (because it's present in the common address space — it's in the house). Likewise, if the process allocates memory, this new memory is available to all the threads as well. The trick here is to recognize whether the memory should be available to all the threads in the process. If it is, then you'll need to have all the threads synchronize their access to it. If it isn't, then we'll assume that it's specific to a particular thread. In that case, since only that thread has access to it, we can assume that no synchronization is required — the thread isn't going to trip itself up!
As we know from everyday life, things aren't quite that simple. Now that we've seen the basic characteristics (summary: everything is shared), let's take a look at where things get a little more interesting, and why.
The diagram below shows the way that we'll be representing threads and processes. The process is the circle, representing the “container” concept (the address space), and the three squigley lines are the threads. You'll see diagrams like this throughout the book.

A process as a container of threads.
If you want to take a shower, and there's someone already using the bathroom, you'll have to wait. How does a thread handle this?
It's done with something called mutual exclusion. It means pretty much what you think — a number of threads are mutually exclusive when it comes to a particular resource.
If you're taking a shower, you want to have exclusive access to the bathroom. To do this, you would typically go into the bathroom and lock the door from the inside. Anyone else trying to use the bathroom would get stopped by the lock. When you're done, you'd unlock the door, allowing someone else access.
This is just what a thread does. A thread uses an object called a mutex (an acronym for MUTual EXclusion). This object is like the lock on a door — once a thread has the mutex locked, no other thread can get the mutex, until the owning thread releases (unlocks) it. Just like the door lock, threads waiting to obtain the mutex will be barred.
Another interesting parallel that occurs with mutexes and door locks is that the mutex is really an “advisory” lock. If a thread doesn't obey the convention of using the mutex, then the protection is useless. In our house analogy, this would be like someone breaking into the washroom through one of the walls ignoring the convention of the door and lock.
What if the bathroom is currently locked and a number of people are waiting to use it? Obviously, all the people are sitting around outside, waiting for whoever is in the bathroom to get out. The real question is, “What happens when the door unlocks? Who gets to go next?”
You'd figure that it would be “fair” to allow whoever is waiting the longest to go next. Or it might be “fair” to let whoever is the oldest go next. Or tallest. Or most important. There are any number of ways to determine what's “fair.”
We solve this with threads via two factors: priority and length of wait.
Suppose two people show up at the (locked) bathroom door at the same time. One of them has a pressing deadline (they're already late for a meeting) whereas the other doesn't. Wouldn't it make sense to allow the person with the pressing deadline to go next? Well, of course it would. The only question is how you decide who's more “important.” This can be done by assigning a priority (let's just use a number like Neutrino does — one is the lowest usable priority, and 255 is the highest as of this version). The people in the house that have pressing deadlines would be given a higher priority, and those that don't would be given a lower priority.
Same thing with threads. A thread inherits its scheduling algorithm from its parent thread, but can call pthread_setschedparam() to change its scheduling policy and priority (if it has the authority to do so).
If a number of threads are waiting, and the mutex becomes unlocked, we would give the mutex to the waiting thread with the highest priority. Suppose, however, that both people have the same priority. Now what do you do? Well, in that case, it would be “fair” to allow the person who's been waiting the longest to go next. This is not only “fair,” but it's also what the Neutrino kernel does. In the case of a bunch of threads waiting, we go primarily by priority, and secondarily by length of wait.
The mutex is certainly not the only synchronization object that we'll encounter. Let's look at some others.
Let's move from the bathroom into the kitchen, since that's a socially acceptable location to have more than one person at the same time. In the kitchen, you may not want to have everyone in there at once. In fact, you probably want to limit the number of people you can have in the kitchen (too many cooks, and all that).
Let's say you don't ever want to have more than two people in there simultaneously. Could you do it with a mutex? Not as we've defined it. Why not? This is actually a very interesting problem for our analogy. Let's break it down into a few steps.
The bathroom can have one of two situations, with two states that go hand-in-hand with each other:
No other combination is possible — the door can't be locked with nobody in the room (how would we unlock it?), and the door can't be unlocked with someone in the room (how would they ensure their privacy?). This is an example of a semaphore with a count of one — there can be at most only one person in that room, or one thread using the semaphore.
The key here (pardon the pun) is the way we characterize the lock. In your typical bathroom lock, you can lock and unlock it only from the inside — there's no outside-accessible key. Effectively, this means that ownership of the mutex is an atomic operation — there's no chance that while you're in the process of getting the mutex some other thread will get it, with the result that you both own the mutex. In our house analogy this is less apparent, because humans are just so much smarter than ones and zeros.
What we need for the kitchen is a different type of lock.
Suppose we installed the traditional key-based lock in the kitchen. The way this lock works is that if you have a key, you can unlock the door and go in. Anyone who uses this lock agrees that when they get inside, they will immediately lock the door from the inside so that anyone on the outside will always require a key.
Well, now it becomes a simple matter to control how many people we want in the kitchen — hang two keys outside the door! The kitchen is always locked. When someone wants to go into the kitchen, they see if there's a key hanging outside the door. If so, they take it with them, unlock the kitchen door, go inside, and use the key to lock the door.
Since the person going into the kitchen must have the key with them when they're in the kitchen, we're directly controlling the number of people allowed into the kitchen at any given point by limiting the number of keys available on the hook outside the door.
With threads, this is accomplished via a semaphore. A “plain” semaphore works just like a mutex — you either own the mutex, in which case you have access to the resource, or you don't, in which case you don't have access. The semaphore we just described with the kitchen is a counting semaphore — it keeps track of the count (by the number of keys available to the threads).
We just asked the question “Could you do it with a mutex?” in relation to implementing a lock with a count, and the answer was no. How about the other way around? Could we use a semaphore as a mutex?
Yes. In fact, in some operating systems, that's exactly what they do — they don't have mutexes, only semaphores! So why bother with mutexes at all?
To answer that question, look at your washroom. How did the builder of your house implement the “mutex”? I suspect you don't have a key hanging on the wall!
Mutexes are a “special purpose” semaphore. If you want one thread running in a particular section of code, a mutex is by far the most efficient implementation.
Later on, we'll look at other synchronization schemes — things called condvars, barriers, and sleepons.
 |
Just so there's no confusion, realize that a mutex has other properties, such as priority inheritance, that differentiate it from a semaphore. |
The house analogy is excellent for getting across the concept of synchronization, but it falls down in one major area. In our house, we had many threads running simultaneously. However, in a real live system, there's typically only one CPU, so only one “thing” can run at once.
Let's look at what happens in the real world, and specifically, the “economy” case where we have one CPU in the system. In this case, since there's only one CPU present, only one thread can run at any given point in time. The kernel decides (using a number of rules, which we'll see shortly) which thread to run, and runs it.
If you buy a system that has multiple, identical CPUs all sharing memory and devices, you have an SMP box (SMP stands for Symmetrical Multi Processor, with the “symmetrical” part indicating that all the CPUs in the system are identical). In this case, the number of threads that can run concurrently (simultaneously) is limited by the number of CPUs. (In reality, this was the case with the single-processor box too!) Since each processor can execute only one thread at a time, with multiple processors, multiple threads can execute simultaneously.
Let's ignore the number of CPUs present for now — a useful abstraction is to design the system as if multiple threads really were running simultaneously, even if that's not the case. A little later on, in the “Things to watch out for when using SMP” section, we'll see some of the non-intuitive impacts of SMP.
So who decides which thread is going to run at any given instant in time? That's the kernel's job.
The kernel determines which thread should be using the CPU at a particular moment, and switches context to that thread. Let's examine what the kernel does with the CPU.
The CPU has a number of registers (the exact number depends on the processor family, e.g., x86 versus MIPS, and the specific family member, e.g., 80486 versus Pentium). When the thread is running, information is stored in those registers (e.g., the current program location).
When the kernel decides that another thread should run, it needs to:
But how does the kernel decide that another thread should run? It looks at whether or not a particular thread is capable of using the CPU at this point. When we talked about mutexes, for example, we introduced a blocking state (this occurred when one thread owned the mutex, and another thread wanted to acquire it as well; the second thread would be blocked).
From the kernel's perspective, therefore, we have one thread that can consume CPU, and one that can't, because it's blocked, waiting for a mutex. In this case, the kernel lets the thread that can run consume CPU, and puts the other thread into an internal list (so that the kernel can track its request for the mutex).
Obviously, that's not a very interesting situation. Suppose that a number of threads can use the CPU. Remember that we delegated access to the mutex based on priority and length of wait? The kernel uses a similar scheme to determine which thread is going to run next. There are two factors: priority and scheduling algorithm, evaluated in that order.
Consider two threads capable of using the CPU. If these threads have different priorities, then the answer is really quite simple — the kernel gives the CPU to the highest priority thread. Neutrino's priorities go from one (the lowest usable) and up, as we mentioned when we talked about obtaining mutexes. Note that priority zero is reserved for the idle thread — you can't use it. (If you want to know the minimum and maximum values for your system, use the functions sched_get_priority_min() and sched_get_priority_max() — they're prototyped in <sched.h>. In this book, we'll assume one as the lowest usable, and 255 as the highest.)
If another thread with a higher priority suddenly becomes able to use the CPU, the kernel will immediately context-switch to the higher priority thread. We call this preemption — the higher-priority thread preempted the lower-priority thread. When the higher-priority thread is done, and the kernel context-switches back to the lower-priority thread that was running before, we call this resumption — the kernel resumes running the previous thread.
Now, suppose that two threads are capable of using the CPU and have the exact same priority.
Let's assume that one of the threads is currently using the CPU. We'll examine the rules that the kernel uses to decide when to context-switch in this case. (Of course, this entire discussion really applies only to threads at the same priority — the instant that a higher-priority thread is ready to use the CPU it gets it; that's the whole point of having priorities in a realtime operating system.)
The two main scheduling algorithms (policies) that the Neutrino kernel understands are Round Robin (or just “RR”) and FIFO (First-In, First-Out). (There's also sporadic scheduling, but it's beyond the scope of this book; see “Sporadic scheduling” in the QNX Neutrino Microkernel chapter of the System Architecture guide.)
In the FIFO scheduling algorithm, a thread is allowed to consume CPU for as long as it wants. This means that if that thread is doing a very long mathematical calculation, and no other thread of a higher priority is ready, that thread could potentially run forever. What about threads of the same priority? They're locked out as well. (It should be obvious at this point that threads of a lower priority are locked out too.)
If the running thread quits or voluntarily gives up the CPU, then the kernel looks for other threads at the same priority that are capable of using the CPU. If there are no such threads, then the kernel looks for lower-priority threads capable of using the CPU. Note that the term “voluntarily gives up the CPU” can mean one of two things. If the thread goes to sleep, or blocks on a semaphore, etc., then yes, a lower-priority thread could run (as described above). But there's also a “special” call, sched_yield() (based on the kernel call SchedYield()), which gives up CPU only to another thread of the same priority — a lower-priority thread would never be given a chance to run if a higher-priority was ready to run. If a thread does in fact call sched_yield(), and no other thread at the same priority is ready to run, the original thread continues running. Effectively, sched_yield() is used to give another thread of the same priority a crack at the CPU.
In the diagram below, we see three threads operating in two different processes:

Three threads in two different processes.
If we assume that threads “A” and “B” are READY, and that thread “C” is blocked (perhaps waiting for a mutex), and that thread “D” (not shown) is currently executing, then this is what a portion of the READY queue that the Neutrino kernel maintains will look like:
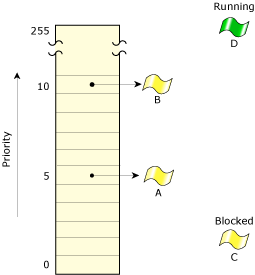
Two threads on the READY queue, one blocked, one running.
This shows the kernel's internal READY queue, which the kernel uses to decide who to schedule next. Note that thread “C” is not on the READY queue, because it's blocked, and thread “D” isn't on the READY queue either because it's running.
The RR scheduling algorithm is identical to FIFO, except that the thread will not run forever if there's another thread at the same priority. It runs only for a system-defined timeslice whose value you can determine by using the function sched_rr_get_interval(). The timeslice is usually 4 ms, but it's actually 4 times the ticksize, which you can query or set with ClockPeriod().
What happens is that the kernel starts an RR thread, and notes the time. If the RR thread is running for a while, the time allotted to it will be up (the timeslice will have expired). The kernel looks to see if there is another thread at the same priority that's ready. If there is, the kernel runs it. If not, then the kernel will continue running the RR thread (i.e., the kernel grants the thread another timeslice).
Let's summarize the scheduling rules (for a single CPU), in order of importance:
The following flowchart shows the decisions that the kernel makes:
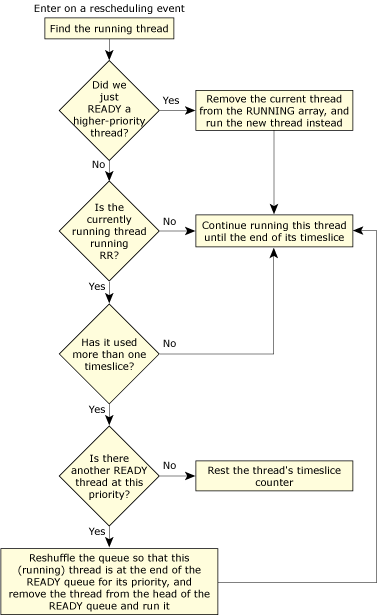
Scheduling roadmap.
For a multiple-CPU system, the rules are the same, except that multiple CPUs can run multiple threads concurrently. The order that the threads run (i.e., which threads get to run on the multiple CPUs) is determined in the exact same way as with a single CPU — the highest-priority READY thread will run on a CPU. For lower-priority or longer-waiting threads, the kernel has some flexibility as to when to schedule them to avoid inefficiency in the use of the cache. For more information about SMP, see the Multicore Processing User's Guide.
We've been talking about “running,” “ready,” and “blocked” loosely — let's now formalize these thread states.
Neutrino's RUNNING state simply means that the thread is now actively consuming the CPU. On an SMP system, there will be multiple threads running; on a single-processor system, there will be one thread running.
The READY state means that this thread could run right now — except that it's not, because another thread, (at the same or higher priority), is running. If two threads were capable of using the CPU, one thread at priority 10 and one thread at priority 7, the priority 10 thread would be RUNNING and the priority 7 thread would be READY.
What do we call the blocked state? The problem is, there's not just one blocked state. Under Neutrino, there are in fact over a dozen blocking states.
Why so many? Because the kernel keeps track of why a thread is blocked.
We saw two blocking states already — when a thread is blocked waiting for a mutex, the thread is in the MUTEX state. When a thread is blocked waiting for a semaphore, it's in the SEM state. These states simply indicate which queue (and which resource) the thread is blocked on.
If a number of threads are blocked on a mutex (in the MUTEX blocked state), they get no attention from the kernel until the thread that owns the mutex releases it. At that point one of the blocked threads is made READY, and the kernel makes a rescheduling decision (if required).
Why “if required?” The thread that just released the mutex could very well still have other things to do and have a higher priority than that of the waiting threads. In this case, we go to the second rule, which states, “The highest-priority ready thread will run,” meaning that the scheduling order has not changed — the higher-priority thread continues to run.
Here's the complete list of kernel blocking states, with brief explanations of each state. By the way, this list is available in <sys/neutrino.h> — you'll notice that the states are all prefixed with STATE_ (for example, “READY” in this table is listed in the header file as STATE_READY):
| If the state is: | The thread is: |
|---|---|
| CONDVAR | Waiting for a condition variable to be signaled. |
| DEAD | Dead. Kernel is waiting to release the thread's resources. |
| INTR | Waiting for an interrupt. |
| JOIN | Waiting for the completion of another thread. |
| MUTEX | Waiting to acquire a mutex. |
| NANOSLEEP | Sleeping for a period of time. |
| NET_REPLY | Waiting for a reply to be delivered across the network. |
| NET_SEND | Waiting for a pulse or message to be delivered across the network. |
| READY | Not running on a CPU, but is ready to run (one or more higher or equal priority threads are running). |
| RECEIVE | Waiting for a client to send a message. |
| REPLY | Waiting for a server to reply to a message. |
| RUNNING | Actively running on a CPU. |
| SEM | Waiting to acquire a semaphore. |
| SEND | Waiting for a server to receive a message. |
| SIGSUSPEND | Waiting for a signal. |
| SIGWAITINFO | Waiting for a signal. |
| STACK | Waiting for more stack to be allocated. |
| STOPPED | Suspended (SIGSTOP signal). |
| WAITCTX | Waiting for a register context (usually floating point) to become available (only on SMP systems). |
| WAITPAGE | Waiting for process manager to resolve a fault on a page. |
| WAITTHREAD | Waiting for a thread to be created. |
The important thing to keep in mind is that when a thread is blocked, regardless of which state it's blocked in, it consumes no CPU. Conversely, the only state in which a thread consumes CPU is in the RUNNING state.
We'll see the SEND, RECEIVE, and REPLY blocked states in the Message Passing chapter. The NANOSLEEP state is used with functions like sleep(), which we'll look at in the chapter on Clocks, Timers, and Getting a Kick Every So Often. The INTR state is used with InterruptWait(), which we'll take a look at in the Interrupts chapter. Most of the other states are discussed in this chapter.
Let's return to our discussion of threads and processes, this time from the perspective of a real live system. Then, we'll take a look at the function calls used to deal with threads and processes.
We know that a process can have one or more threads. (A process that had zero threads wouldn't be able to do anything — there'd be nobody home, so to speak, to actually perform any useful work.) A Neutrino system can have one or more processes. (The same discussion applies — a Neutrino system with zero processes wouldn't do anything.)
So what do these processes and threads do? Ultimately, they form a system — a collection of threads and processes that performs some goal.
At the highest level, the system consists of a number of processes. Each process is responsible for providing a service of some nature — whether it's a filesystem, a display driver, data acquisition module, control module, or whatever.
Within each process, there may be a number of threads. The number of threads varies. One designer using only one thread may accomplish the same functionality as another designer using five threads. Some problems lend themselves to being multi-threaded, and are in fact relatively simple to solve, while other processes lend themselves to being single-threaded, and are difficult to make multi-threaded.
The topic of designing with threads could easily occupy another book — we'll just stick with the basics here.
So why not just have one process with a zillion threads? While some OSes force you to code that way, the advantages of breaking things up into multiple processes are many:
The ability to “break the problem apart” into several independent problems is a powerful concept. It's also at the heart of Neutrino. A Neutrino system consists of many independent modules, each with a certain responsibility. These independent modules are distinct processes. The people at QSS used this trick to develop the modules in isolation, without the modules relying on each other. The only “reliance” the modules would have on each other is through a small number of well-defined interfaces.
This naturally leads to enhanced maintainability, thanks to the lack of interdependencies. Since each module has its own particular definition, it's reasonably easy to fix one module — especially since it's not tied to any other module.
Reliability, though, is perhaps the most important point. A process, just like a house, has some well-defined “borders.” A person in a house has a pretty good idea when they're in the house, and when they're not. A thread has a very good idea — if it's accessing memory within the process, it can live. If it steps out of the bounds of the process's address space, it gets killed. This means that two threads, running in different processes, are effectively isolated from each other.
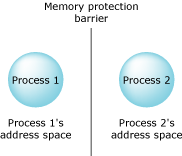
Memory protection.
The process address space is maintained and enforced by Neutrino's process manager module. When a process is started, the process manager allocates some memory to it and starts a thread running. The memory is marked as being owned by that process.
This means that if there are multiple threads in that process, and the kernel needs to context-switch between them, it's a very efficient operation — we don't have to change the address space, just which thread is running. If, however, we have to change to another thread in another process, then the process manager gets involved and causes an address space switch as well. Don't worry — while there's a bit more overhead in this additional step, under Neutrino this is still very fast.
Let's now turn our attention to the function calls available to deal with threads and processes. Any thread can start a process; the only restrictions imposed are those that stem from basic security (file access, privilege restrictions, etc.). In all probability, you've already started other processes; either from the system startup script, the shell, or by having a program start another program on your behalf.
For example, from the shell you can type:
$ program1
This instructs the shell to start a program called program1 and to wait for it to finish. Or, you could type:
$ program2 &
This instructs the shell to start program2 without waiting for it to finish. We say that program2 is running “in the background.”
If you want to adjust the priority of a program before you start it, you could use the nice command, just like in UNIX:
$ nice program3
This instructs the shell to start program3 at a reduced priority.
Or does it?
If you look at what really happens, we told the shell to run a program called nice at the regular priority. The nice command adjusted its own priority to be lower (this is where the name “nice” comes from), and then it ran program3 at that lower priority.
You don't usually care about the fact that the shell creates processes — this is a basic assumption about the shell. In some application designs, you'll certainly be relying on shell scripts (batches of commands in a file) to do the work for you, but in other cases you'll want to create the processes yourself.
For example, in a large multi-process system, you may want to have one master program start all the other processes for your application based on some kind of configuration file. Another example would include starting up processes when certain operating conditions (events) have been detected.
Let's take a look at the functions that Neutrino provides for starting up other processes (or transforming into a different program):
Which function you use depends on two requirements: portability and functionality. As usual, there's a trade-off between the two.
The common thing that happens in all the calls that create a new process is the following. A thread in the original process calls one of the above functions. Eventually, the function gets the process manager to create an address space for a new process. Then, the kernel starts a thread in the new process. This thread executes a few instructions, and calls main(). (In the case of fork() and vfork(), of course, the new thread begins execution in the new process by returning from the fork() or vfork(); we'll see how to deal with this shortly.)
The system() function is the simplest; it takes a command line, the same as you'd type it at a shell prompt, and executes it.
In fact, system() actually starts up a shell to handle the command that you want to perform.
The editor that I'm using to write this book makes use of the system() call. When I'm editing, I may need to “shell out,” check out some samples, and then come back into the editor, all without losing my place. In this editor, I may issue the command :!pwd for example, to display the current working directory. The editor runs this code for the :!pwd command:
system ("pwd");
Is system() suited for everything under the sun? Of course not, but it's useful for a lot of your process-creation requirements.
Let's look at some of the other process-creation functions.
The next process-creation functions we should look at are the exec() and spawn() families. Before we go into the details, let's see what the differences are between these two groups of functions.
The exec() family transforms the current process into another one. What I mean by that is that when a process issues an exec() function call, that process ceases to run the current program and begins to run another program. The process ID doesn't change — that process changed into another program. What happened to all the threads in the process? We'll come back to that when we look at fork().
The spawn() family, on the other hand, doesn't do that. Calling a member of the spawn() family creates another process (with a new process ID) that corresponds to the program specified in the function's arguments.
Let's look at the different variants of the spawn() and exec() functions. In the table that follows, you'll see which ones are POSIX and which aren't. Of course, for maximum portability, you'll want to use only the POSIX functions.
| Spawn | POSIX? | Exec | POSIX? |
|---|---|---|---|
| spawn() | No | ||
| spawnl() | No | execl() | Yes |
| spawnle() | No | execle() | Yes |
| spawnlp() | No | execlp() | Yes |
| spawnlpe() | No | execlpe() | No |
| spawnp() | No | ||
| spawnv() | No | execv() | Yes |
| spawnve() | No | execve() | Yes |
| spawnvp() | No | execvp() | Yes |
| spawnvpe() | No | execvpe() | No |
While these variants might appear to be overwhelming, there is a pattern to their suffixes:
| A suffix of: | Means: |
|---|---|
| l (lowercase “L”) | The argument list is specified via a list of parameters given in the call itself, terminated by a NULL argument. |
| e | An environment is specified. |
| p | The PATH environment variable is used in case the full pathname to the program isn't specified. |
| v | The argument list is specified via a pointer to an argument vector. |
The argument list is a list of command-line arguments passed to the program.
Also, note that in the C library, spawnlp(), spawnvp(), and spawnlpe() all call spawnvpe(), which in turn calls spawnp(). The functions spawnle(), spawnv(), and spawnl() all eventually call spawnve(), which then calls spawn(). Finally, spawnp() calls spawn(). So, the root of all spawning functionality is the spawn() call.
Let's now take a look at the various spawn() and exec() variants in detail so that you can get a feel for the various suffixes used. Then, we'll see the spawn() call itself.
For example, if I want to invoke the ls command with the arguments -t, -r, and -l (meaning “sort the output by time, in reverse order, and show me the long version of the output”), I could specify it as either:
/* To run ls and keep going: */
spawnl (P_WAIT, "/bin/ls", "/bin/ls", "-t", "-r", "-l", NULL);
/* To transform into ls: */
execl ("/bin/ls", "/bin/ls", "-t", "-r", "-l", NULL);
or, using the v suffix variant:
char *argv [] =
{
"/bin/ls",
"-t",
"-r",
"-l",
NULL
};
/* To run ls and keep going: */
spawnv (P_WAIT, "/bin/ls", argv);
/* To transform into ls: */
execv ("/bin/ls", argv);
Why the choice? It's provided as a convenience. You may have a parser already built into your program, and it would be convenient to pass around arrays of strings. In that case, I'd recommend using the “v” suffix variants. Or, you may be coding up a call to a program where you know what the parameters are. In that case, why bother setting up an array of strings when you know exactly what the arguments are? Just pass them to the “l” suffix variant.
Note that we passed the actual pathname of the program (/bin/ls) and the name of the program again as the first argument. We passed the name again to support programs that behave differently based on how they're invoked.
For example, the GNU compression and decompression utilities (gzip and gunzip) are actually links to the same executable. When the executable starts, it looks at argv [0] (passed to main()) and decides whether it should compress or decompress.
The “e” suffix versions pass an environment to the program. An environment is just that — a kind of “context” for the program to operate in. For example, you may have a spelling checker that has a dictionary of words. Instead of specifying the dictionary's location every time on the command line, you could provide it in the environment:
$ export DICTIONARY=/home/rk/.dict $ spellcheck document.1
The export command tells the shell to create a new environment variable (in this case, DICTIONARY), and assign it a value (/home/rk/.dict).
If you ever wanted to use a different dictionary, you'd have to alter the environment before running the program. This is easy from the shell:
$ export DICTIONARY=/home/rk/.altdict $ spellcheck document.1
But how can you do this from your own programs? To use the “e” versions of spawn() and exec(), you specify an array of strings representing the environment:
char *env [] =
{
"DICTIONARY=/home/rk/.altdict",
NULL
};
// To start the spell-checker:
spawnle (P_WAIT, "/usr/bin/spellcheck", "/usr/bin/spellcheck",
"document.1", NULL, env);
// To transform into the spell-checker:
execle ("/usr/bin/spellcheck", "/usr/bin/spellcheck",
"document.1", NULL, env);
The “p” suffix versions will search the directories in your PATH environment variable to find the executable. You've probably noticed that all the examples have a hard-coded location for the executable — /bin/ls and /usr/bin/spellcheck. What about other executables? Unless you want to first find out the exact path for that particular program, it would be best to have the user tell your program all the places to search for executables. The standard PATH environment variable does just that. Here's the one from a minimal system:
PATH=/proc/boot:/bin
This tells the shell that when I type a command, it should first look in the directory /proc/boot, and if it can't find the command there, it should look in the binaries directory /bin part. PATH is a colon-separated list of places to look for commands. You can add as many elements to the PATH as you want, but keep in mind that all pathname components will be searched (in order) for the executable.
If you don't know the path to the executable, then you can use the “p” variants. For example:
// Using an explicit path:
execl ("/bin/ls", "/bin/ls", "-l", "-t", "-r", NULL);
// Search your PATH for the executable:
execlp ("ls", "ls", "-l", "-t", "-r", NULL);
If execl() can't find ls in /bin, it returns an error. The execlp() function will search all the directories specified in the PATH for ls, and will return an error only if it can't find ls in any of those directories. This is also great for multiplatform support — your program doesn't have to be coded to know about the different CPU names, it just finds the executable.
What if you do something like this?
execlp ("/bin/ls", "ls", "-l", "-t", "-r", NULL);
Does it search the environment? No. You told execlp() to use an explicit pathname, which overrides the normal PATH searching rule. If it doesn't find ls in /bin that's it, no other attempts are made (this is identical to the way execl() works in this case).
Is it dangerous to mix an explicit path with a plain command name (e.g., the path argument /bin/ls, and the command name argument ls, instead of /bin/ls)? This is usually pretty safe, because:
The only compelling reason for specifying the full pathname for the first argument is that the program can print out diagnostics including this first argument, which can instantly tell you where the program was invoked from. This may be important when the program can be found in multiple locations along the PATH.
The spawn() functions all have an extra parameter; in all the above examples, I've always specified P_WAIT. There are four flags you can pass to spawn() to change its behavior:
It's generally clearer to use the exec() call if that's what you meant — it saves the maintainer of the software from having to look up P_OVERLAY in the C Library Reference!
As we mentioned above, all spawn() functions eventually call the plain spawn() function. Here's the prototype for the spawn() function:
#include <spawn.h>
pid_t
spawn (const char *path,
int fd_count,
const int fd_map [],
const struct inheritance *inherit,
char * const argv [],
char * const envp []);
We can immediately dispense with the path, argv, and envp parameters — we've already seen those above as representing the location of the executable (the path member), the argument vector (argv), and the environment (envp).
The fd_count and fd_map parameters go together. If you specify zero for fd_count, then fd_map is ignored, and it means that all file descriptors (except those modified by fcntl()'s FD_CLOEXEC flag) will be inherited in the newly created process. If the fd_count is non-zero, then it indicates the number of file descriptors contained in fd_map; only the specified ones will be inherited.
The inherit parameter is a pointer to a structure that contains a set of flags, signal masks, and so on. For more details, you should consult the Neutrino Library Reference.
Suppose you want to create a new process that's identical to the currently running process and have it run concurrently. You could approach this with a spawn() (and the P_NOWAIT parameter), giving the newly created process enough information about the exact state of your process so it could set itself up. However, this can be extremely complicated; describing the “current state” of the process can involve lots of data.
There is an easier way — the fork() function, which duplicates the current process. All the code is the same, and the data is the same as the creating (or parent) process's data.
Of course, it's impossible to create a process that's identical in every way to the parent process. Why? The most obvious difference between these two processes is going to be the process ID — we can't create two processes with the same process ID. If you look at fork()'s documentation in the Neutrino Library Reference, you'll see that there is a list of differences between the two processes. You should read this list to be sure that you know these differences if you plan to use fork().
If both sides of a fork() look alike, how do you tell them apart? When you call fork(), you create another process executing the same code at the same location (i.e., both are about to return from the fork() call) as the parent process. Let's look at some sample code:
int main (int argc, char **argv)
{
int retval;
printf ("This is most definitely the parent process\n");
fflush (stdout);
retval = fork ();
printf ("Which process printed this?\n");
return (EXIT_SUCCESS);
}
After the fork() call, both processes are going to execute the second printf() call! If you run this program, it prints something like this:
This is most definitely the parent process Which process printed this? Which process printed this?
Both processes print the second line.
The only way to tell the two processes apart is the fork() return value in retval. In the newly created child process, retval is zero; in the parent process, retval is the child's process ID.
Clear as mud? Here's another code snippet to clarify:
printf ("The parent is pid %d\n", getpid ());
fflush (stdout);
if (child_pid = fork ()) {
printf ("This is the parent, child pid is %d\n",
child_pid);
} else {
printf ("This is the child, pid is %d\n",
getpid ());
}
This program will print something like:
The parent is pid 4496 This is the parent, child pid is 8197 This is the child, pid is 8197
You can tell which process you are (the parent or the child) after the fork() by looking at fork()'s return value.
The vfork() function can be a lot less resource intensive than the plain fork(), because it shares the parent's address space.
The vfork() function creates a child, but then suspends the parent thread until the child calls exec() or exits (via exit() and friends). Additionally, vfork() will work on physical memory model systems, whereas fork() can't — fork() needs to create the same address space, which just isn't possible in a physical memory model.
Suppose you have a process and you haven't created any threads yet (i.e., you're running with one thread, the one that called main()). When you call fork(), another process is created, also with one thread. This is the simple case.
Now suppose that in your process, you've called pthread_create() to create another thread. When you call fork(), it will now return ENOSYS (meaning that the function is not supported)! Why?
Well, believe it or not, this is POSIX compatible — POSIX says that fork() can return ENOSYS. What actually happens is this: the Neutrino C library isn't built to handle the forking of a process with threads. When you call pthread_create(), the pthread_create() function sets a flag, effectively saying, “Don't let this process fork(), because I'm not prepared to handle it.” Then, in the library fork() function, this flag is checked, and, if set, causes fork() to return ENOSYS.
The reason this is intentionally done has to do with threads and mutexes. If this restriction weren't in place (and it may be lifted in a future release) the newly created process would have the same number of threads as the original process. This is what you'd expect. However, the complication occurs because some of the original threads may own mutexes. Since the newly created process has the identical contents of the data space of the original process, the library would have to keep track of which mutexes were owned by which threads in the original process, and then duplicate that ownership in the new process. This isn't impossible — there's a function called pthread_atfork() that allows a process to deal with this; however, the functionality of calling pthread_atfork() isn't being used by all the mutexes in the Neutrino C library as of this writing.
Obviously, if you're porting existing code, you'll want to use whatever the existing code uses. For new code, you should avoid fork() if at all possible. Here's why:
The choice between vfork() and the spawn() family boils down to portability, and what you want the child and parent to be doing. The vfork() function will pause until the child calls exec() or exits, whereas the spawn() family of functions can allow both to run concurrently. The vfork() function, however, is subtly different between operating systems.
Now that we've seen how to start another process, let's see how to start another thread.
Any thread can create another thread in the same process; there are no restrictions (short of memory space, of course!). The most common way of doing this is via the POSIX pthread_create() call:
#include <pthread.h>
int
pthread_create (pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine) (void *),
void *arg);
The pthread_create() function takes four arguments:
Note that the thread pointer and the attributes structure (attr) are optional — you can pass them as NULL.
The thread parameter can be used to store the thread ID of the newly created thread. You'll notice that in the examples below, we'll pass a NULL, meaning that we don't care what the ID is of the newly created thread. If we did care, we could do something like this:
pthread_t tid;
pthread_create (&tid, …
printf ("Newly created thread id is %d\n", tid);
This use is actually quite typical, because you'll often want to know which thread ID is running which piece of code.
|
A small subtle point. It's possible that the newly created thread may be running before the thread ID (the tid parameter) is filled. This means that you should be careful about using the tid as a global variable. The usage shown above is okay, because the pthread_create() call has returned, which means that the tid value is stuffed correctly. |
The new thread begins executing at start_routine(), with the argument arg.
When you start a new thread, it can assume some well-defined defaults, or you can explicitly specify its characteristics.
Before we jump into a discussion of the thread attribute functions, let's look at the pthread_attr_t data type:
typedef struct {
int __flags;
size_t __stacksize;
void *__stackaddr;
void (*__exitfunc)(void *status);
int __policy;
struct sched_param __param;
unsigned __guardsize;
} pthread_attr_t;
Basically, the fields are used as follows:
The following functions are available:
This looks like a pretty big list (20 functions), but in reality we have to worry about only half of them, because they're paired: “get” and “set” (with the exception of pthread_attr_init() and pthread_attr_destroy()).
Before we examine the attribute functions, there's one thing to note. You must call pthread_attr_init() to initialize the attribute structure before using it, set it with the appropriate pthread_attr_set*() function(s), and then call pthread_create() to create the thread. Changing the attribute structure after the thread's been created has no effect.
The function pthread_attr_init() must be called to initialize the attribute structure before using it:
… pthread_attr_t attr; … pthread_attr_init (&attr);
You could call pthread_attr_destroy() to “uninitialize” the thread attribute structure, but almost no one ever does (unless you have POSIX-compliant code).
In the descriptions that follow, I've marked the default values with “(default).”
The three functions, pthread_attr_setdetachstate(), pthread_attr_setinheritsched(), and pthread_attr_setscope() determine whether the thread is created “joinable” or “detached,” whether the thread inherits the scheduling attributes of the creating thread or uses the scheduling attributes specified by pthread_attr_setschedparam() and pthread_attr_setschedpolicy(), and finally whether the thread has a scope of “system” or “process.”
To create a “joinable” thread (meaning that another thread can synchronize to its termination via pthread_join()), you'd use:
(default) pthread_attr_setdetachstate (&attr, PTHREAD_CREATE_JOINABLE);
To create one that can't be joined (called a “detached” thread), you'd use:
pthread_attr_setdetachstate (&attr, PTHREAD_CREATE_DETACHED);
If you want the thread to inherit the scheduling attributes of the creating thread (that is, to have the same scheduling algorithm and the same priority), you'd use:
(default) pthread_attr_setinheritsched (&attr, PTHREAD_INHERIT_SCHED);
To create one that uses the scheduling attributes specified in the attribute structure itself (which you'd set using pthread_attr_setschedparam() and pthread_attr_setschedpolicy()), you'd use:
pthread_attr_setinheritsched (&attr, PTHREAD_EXPLICIT_SCHED);
Finally, you'd never call pthread_attr_setscope(). Why? Because Neutrino supports only “system” scope, and it's the default when you initialize the attribute. (“System” scope means that all threads in the system compete against each other for CPU; the other value, “process,” means that threads compete against each other for CPU within the process, and the kernel schedules the processes.)
If you do insist on calling it, you can call it only as follows:
(default) pthread_attr_setscope (&attr, PTHREAD_SCOPE_SYSTEM);
The thread attribute stack parameters are prototyped as follows:
int pthread_attr_setguardsize (pthread_attr_t *attr, size_t gsize); int pthread_attr_setstackaddr (pthread_attr_t *attr, void *addr); int pthread_attr_setstacksize (pthread_attr_t *attr, size_t ssize); int pthread_attr_setstacklazy (pthread_attr_t *attr, int lazystack);
These functions all take the attribute structure as their first parameter; their second parameters are selected from the following:
The guard area is a memory area immediately after the stack that the thread can't write to. If it does (meaning that the stack was about to overflow), the thread will get hit with a SIGSEGV. If the guardsize is 0, it means that there's no guard area. This also implies that there's no stack overflow checking. If the guardsize is nonzero, then it's set to at least the system-wide default guardsize (which you can obtain with a call to sysconf() with the constant _SC_PAGESIZE). Note that the guardsize will be at least as big as a “page” (for example, 4 KB on an x86 processor). Also, note that the guard page doesn't take up any physical memory — it's done as a virtual address (MMU) “trick.”
The addr is the address of the stack, in case you're providing it. You can set it to NULL meaning that the system will allocate (and will free!) the stack for the thread. The advantage of specifying a stack is that you can do postmortem stack depth analysis. This is accomplished by allocating a stack area, filling it with a “signature” (for example, the string “STACK” repeated over and over), and letting the thread run. When the thread has completed, you'd look at the stack area and see how far the thread had scribbled over your signature, giving you the maximum depth of the stack used during this particular run.
The ssize parameter specifies how big the stack is. If you provide the stack in addr, then ssize should be the size of that data area. If you don't provide the stack in addr (meaning you passed a NULL), then the ssize parameter tells the system how big a stack it should allocate for you. If you specify a 0 for ssize, the system will select the default stack size for you. Obviously, it's bad practice to specify a 0 for ssize and specify a stack using addr — effectively you're saying “Here's a pointer to an object, and the object is some default size.” The problem is that there's no binding between the object size and the passed value.
|
If a stack is being provided via addr, no automatic stack overflow protection exists for that thread (i.e., there's no guard area). However, you can certainly set this up yourself using mmap() and mprotect(). |
Finally, the lazystack parameter indicates if the physical memory should be allocated as required (use the value PTHREAD_STACK_LAZY) or all up front (use the value PTHREAD_STACK_NOTLAZY). The advantage of allocating the stack “on demand” (as required) is that the thread won't use up more physical memory than it absolutely has to. The disadvantage (and hence the advantage of the “all up front” method) is that in a low-memory environment the thread won't mysteriously die some time during operating when it needs that extra bit of stack, and there isn't any memory left. If you are using PTHREAD_STACK_NOTLAZY, you'll most likely want to set the actual size of the stack instead of accepting the default, because the default is quite large.
Finally, if you do specify PTHREAD_EXPLICIT_SCHED for pthread_attr_setinheritsched(), then you'll need a way to specify both the scheduling algorithm and the priority of the thread you're about to create.
This is done with the two functions:
int
pthread_attr_setschedparam (pthread_attr_t *attr,
const struct sched_param *param);
int
pthread_attr_setschedpolicy (pthread_attr_t *attr,
int policy);
The policy is simple — it's one of SCHED_FIFO, SCHED_RR, or SCHED_OTHER.
|
SCHED_OTHER is currently mapped to SCHED_RR. |
The param is a structure that contains one member of relevance here: sched_priority. Set this value via direct assignment to the desired priority.
|
A common bug to watch out for is specifying PTHREAD_EXPLICIT_SCHED and
then setting only the scheduling policy.
The problem is that in an initialized attribute structure, the value of param.sched_priority
is 0.
This is the same priority as the IDLE process, meaning that your newly created thread will be
competing for CPU with the IDLE process.
Been there, done that, got the T-shirt. :-) Enough people have been bitten by this that QSS has made priority zero reserved for only the idle thread. You simply cannot run a thread at priority zero. |
Let's take a look at some examples. We'll assume that the proper include files (<pthread.h> and <sched.h>) have been included, and that the thread to be created is called new_thread() and is correctly prototyped and defined.
The most common way of creating a thread is to simply let the values default:
pthread_create (NULL, NULL, new_thread, NULL);
In the above example, we've created our new thread with the defaults, and passed it a NULL as its one and only parameter (that's the third NULL in the pthread_create() call above).
Generally, you can pass anything you want (via the arg field) to your new thread. Here we're passing the number 123:
pthread_create (NULL, NULL, new_thread, (void *) 123);
A more complicated example is to create a non-joinable thread with round-robin scheduling at priority 15:
pthread_attr_t attr; // initialize the attribute structure pthread_attr_init (&attr); // set the detach state to "detached" pthread_attr_setdetachstate (&attr, PTHREAD_CREATE_DETACHED); // override the default of INHERIT_SCHED pthread_attr_setinheritsched (&attr, PTHREAD_EXPLICIT_SCHED); pthread_attr_setschedpolicy (&attr, SCHED_RR); attr.param.sched_priority = 15; // finally, create the thread pthread_create (NULL, &attr, new_thread, NULL);
To see what a multithreaded program “looks like,” you could run the pidin command from the shell. Say our program was called spud. If we run pidin once before spud created a thread and once after spud created two more threads (for three total), here's what the output would look like (I've shortened the pidin output to show only spud):
# pidin pid tid name prio STATE Blocked 12301 1 spud 10r READY # pidin pid tid name prio STATE Blocked 12301 1 spud 10r READY 12301 2 spud 10r READY 12301 3 spud 10r READY
As you can see, the process spud (process ID 12301) has three threads (under the “tid” column). The three threads are running at priority 10 with a scheduling algorithm of round robin (indicated by the “r” after the 10). All three threads are READY, meaning that they're able to use CPU but aren't currently running on the CPU (another, higher-priority thread, is currently running).
Now that we know all about creating threads, let's take a look at how and where we'd use them.
There are two classes of problems where the application of threads is a good idea.
|
Threads are like overloading operators in C++ — it may seem like a good idea (at the time) to overload every single operator with some interesting use, but it makes the code hard to understand. Similarly with threads, you could create piles of threads, but the additional complexity will make your code hard to understand, and therefore hard to maintain. Judicious use of threads, on the other hand, will result in code that is functionally very clean. |
Threads are great where you can parallelize operations — a number of mathematical problems spring to mind (graphics, digital signal processing, etc.). Threads are also great where you want a program to perform several independent functions while sharing data, such as a web-server that's serving multiple clients simultaneously. We'll examine these two classes.
Suppose that we have a graphics program that performs ray tracing. Each raster line on the screen is dependent on the main database (which describes the actual picture being generated). The key here is this: each raster line is independent of the others. This immediately causes the problem to stand out as a threadable program.
Here's the single-threaded version:
int
main (int argc, char **argv)
{
int x1;
… // perform initializations
for (x1 = 0; x1 < num_x_lines; x1++) {
do_one_line (x1);
}
… // display results
}
Here we see that the program will iterate x1 over all the raster lines that are to be calculated.
On an SMP system, this program will use only one of the CPUs. Why? Because we haven't told the operating system to do anything in parallel. The operating system isn't smart enough to look at the program and say, “Hey, hold on a second! We have 4 CPUs, and it looks like there are independent execution flows here. I'll run it on all 4 CPUs!”
So, it's up to the system designer (you) to tell Neutrino which parts can be run in parallel. The easiest way to do that would be:
int
main (int argc, char **argv)
{
int x1;
… // perform initializations
for (x1 = 0; x1 < num_x_lines; x1++) {
pthread_create (NULL, NULL, do_one_line, (void *) x1);
}
… // display results
}
There are a number of problems with this simplistic approach. First of all (and this is most minor), the do_one_line() function would have to be modified to take a void * instead of an int as its argument. This is easily remedied with a typecast.
The second problem is a little bit trickier. Let's say that the screen resolution that you were computing the picture for was 1280 by 1024. We'd be creating 1280 threads! This is not a problem for Neutrino — Neutrino “limits” you to 32767 threads per process! However, each thread must have a unique stack. If your stack is a reasonable size (say 8 KB), you'll have used 1280 × 8 KB (10 megabytes!) of stack. And for what? There are only 4 processors in your SMP system. This means that only 4 of the 1280 threads will run at a time — the other 1276 threads are waiting for a CPU. (In reality, the stack will “fault in,” meaning that the space for it will be allocated only as required. Nonetheless, it's a waste — there are still other overheads.)
A much better solution to this would be to break the problem up into 4 pieces (one for each CPU), and start a thread for each piece:
int num_lines_per_cpu;
int num_cpus;
int
main (int argc, char **argv)
{
int cpu;
… // perform initializations
// get the number of CPUs
num_cpus = _syspage_ptr -> num_cpu;
num_lines_per_cpu = num_x_lines / num_cpus;
for (cpu = 0; cpu < num_cpus; cpu++) {
pthread_create (NULL, NULL,
do_one_batch, (void *) cpu);
}
… // display results
}
void *
do_one_batch (void *c)
{
int cpu = (int) c;
int x1;
for (x1 = 0; x1 < num_lines_per_cpu; x1++) {
do_line_line (x1 + cpu * num_lines_per_cpu);
}
}
Here we're starting only num_cpus threads. Each thread will run on one CPU. And since we have only a small number of threads, we're not wasting memory with unnecessary stacks. Notice how we got the number of CPUs by dereferencing the “System Page” global variable _syspage_ptr. (For more information about what's in the system page, please consult QSS's Building Embedded Systems book or the <sys/syspage.h> include file).
The best part about this code is that it will function just fine on a single-processor system — you'll create only one thread, and have it do all the work. The additional overhead (one stack) is well worth the flexibility of having the software “just work faster” on an SMP box.
I mentioned that there were a number of problems with the simplistic code sample initially shown. Another problem with it is that main() starts up a bunch of threads and then displays the results. How does the function know when it's safe to display the results?
To have the main() function poll for completion would defeat the purpose of a realtime operating system:
int
main (int argc, char **argv)
{
…
// start threads as before
while (num_lines_completed < num_x_lines) {
sleep (1);
}
}
Don't even consider writing code like this!
There are two elegant solutions to this problem: pthread_join() and pthread_barrier_wait().
The simplest method of synchronization is to join the threads as they terminate. Joining really means waiting for termination.
Joining is accomplished by one thread waiting for the termination of another thread. The waiting thread calls pthread_join():
#include <pthread.h> int pthread_join (pthread_t thread, void **value_ptr);
To use pthread_join(), you pass it the thread ID of the thread that you wish to join, and an optional value_ptr, which can be used to store the termination return value from the joined thread. (You can pass in a NULL if you aren't interested in this value — we're not, in this case.)
Where did the thread ID came from? We ignored it in the pthread_create() — we passed in a NULL for the first parameter. Let's now correct our code:
int num_lines_per_cpu, num_cpus;
int main (int argc, char **argv)
{
int cpu;
pthread_t *thread_ids;
… // perform initializations
thread_ids = malloc (sizeof (pthread_t) * num_cpus);
num_lines_per_cpu = num_x_lines / num_cpus;
for (cpu = 0; cpu < num_cpus; cpu++) {
pthread_create (&thread_ids [cpu], NULL,
do_one_batch, (void *) cpu);
}
// synchronize to termination of all threads
for (cpu = 0; cpu < num_cpus; cpu++) {
pthread_join (thread_ids [cpu], NULL);
}
… // display results
}
You'll notice that this time we passed the first argument to pthread_create() as a pointer to a pthread_t. This is where the thread ID of the newly created thread gets stored. After the first for loop finishes, we have num_cpus threads running, plus the thread that's running main(). We're not too concerned about the main() thread consuming all our CPU; it's going to spend its time waiting.
The waiting is accomplished by doing a pthread_join() to each of our threads in turn. First, we wait for thread_ids [0] to finish. When it completes, the pthread_join() will unblock. The next iteration of the for loop will cause us to wait for thread_ids [1] to finish, and so on, for all num_cpus threads.
A common question that arises at this point is, “What if the threads finish in the reverse order?” In other words, what if there are 4 CPUs, and, for whatever reason, the thread running on the last CPU (CPU 3) finishes first, and then the thread running on CPU 2 finishes next, and so on? Well, the beauty of this scheme is that nothing bad happens.
The first thing that's going to happen is that the pthread_join() will block on thread_ids [0]. Meanwhile, thread_ids [3] finishes. This has absolutely no impact on the main() thread, which is still waiting for the first thread to finish. Then thread_ids [2] finishes. Still no impact. And so on, until finally thread_ids [0] finishes, at which point, the pthread_join() unblocks, and we immediately proceed to the next iteration of the for loop. The second iteration of the for loop executes a pthread_join() on thread_ids [1], which will not block — it returns immediately. Why? Because the thread identified by thread_ids [1] is already finished. Therefore, our for loop will “whip” through the other threads, and then exit. At that point, we know that we've synched up with all the computational threads, so we can now display the results.
When we talked about the synchronization of the main() function to the completion of the worker threads (in “Synchronizing to the termination of a thread,” above), we mentioned two methods: pthread_join(), which we've looked at, and a barrier.
Returning to our house analogy, suppose that the family wanted to take a trip somewhere. The driver gets in the minivan and starts the engine. And waits. The driver waits until all the family members have boarded, and only then does the van leave to go on the trip — we can't leave anyone behind!
This is exactly what happened with the graphics example. The main thread needs to wait until all the worker threads have completed, and only then can the next part of the program begin.
Note an important distinction, however. With pthread_join(), we're waiting for the termination of the threads. This means that the threads are no longer with us; they've exited.
With the barrier, we're waiting for a certain number of threads to rendezvous at the barrier. Then, when the requisite number are present, we unblock all of them. (Note that the threads continue to run.)
You first create a barrier with pthread_barrier_init():
#include <pthread.h>
int
pthread_barrier_init (pthread_barrier_t *barrier,
const pthread_barrierattr_t *attr,
unsigned int count);
This creates a barrier object at the passed address (pointer to the barrier object is in barrier), with the attributes as specified by attr (we'll just use NULL to get the defaults). The number of threads that must call pthread_barrier_wait() is passed in count.
Once the barrier is created, we then want each of the threads to call pthread_barrier_wait() to indicate that it has completed:
#include <pthread.h> int pthread_barrier_wait (pthread_barrier_t *barrier);
When a thread calls pthread_barrier_wait(), it will block until the number of threads specified initially in the pthread_barrier_init() have called pthread_barrier_wait() (and blocked too). When the correct number of threads have called pthread_barrier_wait(), all those threads will “simultaneously” unblock.
Here's an example:
/*
* barrier1.c
*/
#include <stdio.h>
#include <time.h>
#include <pthread.h>
#include <sys/neutrino.h>
pthread_barrier_t barrier; // the barrier synchronization object
void *
thread1 (void *not_used)
{
time_t now;
char buf [27];
time (&now);
printf ("thread1 starting at %s", ctime_r (&now, buf));
// do the computation
// let's just do a sleep here...
sleep (20);
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in thread1() done at %s", ctime_r (&now, buf));
}
void *
thread2 (void *not_used)
{
time_t now;
char buf [27];
time (&now);
printf ("thread2 starting at %s", ctime_r (&now, buf));
// do the computation
// let's just do a sleep here...
sleep (40);
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in thread2() done at %s", ctime_r (&now, buf));
}
main () // ignore arguments
{
time_t now;
char buf [27];
// create a barrier object with a count of 3
pthread_barrier_init (&barrier, NULL, 3);
// start up two threads, thread1 and thread2
pthread_create (NULL, NULL, thread1, NULL);
pthread_create (NULL, NULL, thread2, NULL);
// at this point, thread1 and thread2 are running
// now wait for completion
time (&now);
printf ("main () waiting for barrier at %s", ctime_r (&now, buf));
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in main () done at %s", ctime_r (&now, buf));
}
The main thread created the barrier object and initialized it with a count of how many threads (including itself!) should be synchronized to the barrier before it “breaks through.” In our sample, this was a count of 3 — one for the main() thread, one for thread1(), and one for thread2(). Then the graphics computational threads (thread1() and thread2() in our case here) are started, as before. For illustration, instead of showing source for graphics computations, we just stuck in a sleep (20); and sleep (40); to cause a delay, as if computations were occurring. To synchronize, the main thread simply blocks itself on the barrier, knowing that the barrier will unblock only after the worker threads have joined it as well.
As mentioned earlier, with the pthread_join(), the worker threads are done and dead in order for the main thread to synchronize with them. But with the barrier, the threads are alive and well. In fact, they've just unblocked from the pthread_barrier_wait() when all have completed. The wrinkle introduced here is that you should be prepared to do something with these threads! In our graphics example, there's nothing for them to do (as we've written it). In real life, you may wish to start the next frame calculations.
Suppose that we modify our example slightly so that we can illustrate why it's also sometimes a good idea to have multiple threads even on a single-CPU system.
In this modified example, one node on a network is responsible for calculating the raster lines (same as the graphics example, above). However, when a line is computed, its data should be sent over the network to another node, which will perform the display functions. Here's our modified main() (from the original example, without threads):
int
main (int argc, char **argv)
{
int x1;
… // perform initializations
for (x1 = 0; x1 < num_x_lines; x1++) {
do_one_line (x1); // "C" in our diagram, below
tx_one_line_wait_ack (x1); // "X" and "W" in diagram below
}
}
You'll notice that we've eliminated the display portion and instead added a tx_one_line_wait_ack() function. Let's further suppose that we're dealing with a reasonably slow network, but that the CPU doesn't really get involved in the transmission aspects — it fires the data off to some hardware that then worries about transmitting it. The tx_one_line_wait_ack() uses a bit of CPU to get the data to the hardware, but then uses no CPU while it's waiting for the acknowledgment from the far end.
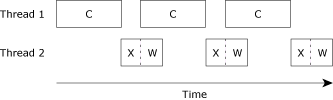
Here's a diagram showing the CPU usage (we've used “C” for the graphics compute part, “X” for the transmit part, and “W” for waiting for the acknowledgment from the far end):
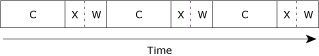
Serialized, single CPU.
Wait a minute! We're wasting precious seconds waiting for the hardware to do its thing!
If we made this multithreaded, we should be able to get much better use of our CPU, right?
Multithreaded, single CPU.
This is much better, because now, even though the second thread spends a bit of its time waiting, we've reduced the total overall time required to compute.
If our times were Tcompute to compute, Ttx to transmit, and Twait to let the hardware do its thing, in the first case our total running time would be:
(Tcompute + Ttx + Twait) × num_x_lines
whereas with the two threads it would be
(Tcompute + Ttx) × num_x_lines + Twait
which is shorter by
Twait × (num_x_lines - 1)
assuming of course that Twait ≤ Tcompute.
|
Note that we will ultimately be constrained by:
Tcompute + Ttx × num_x_lines because we'll have to incur at least one full computation, and we'll have to transmit the data out the hardware — while we can use multithreading to overlay the computation cycles, we have only one hardware resource for the transmit. |
Now, if we created a four-thread version and ran it on an SMP system with 4 CPUs, we'd end up with something that looked like this:
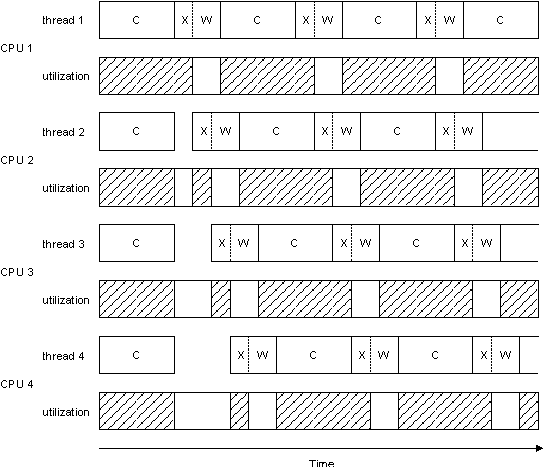
Four threads, four CPUs.
Notice how each of the four CPUs is underutilized (as indicated by the empty rectangles in the “utilization” graph). There are two interesting areas in the figure above. When the four threads start, they each compute. Unfortunately, when the threads are finished each computation, they're contending for the transmit hardware (the “X” parts in the figure are offset — only one transmission may be in progress at a time). This gives us a small anomaly in the startup part. Once the threads are past this stage, they're naturally synchronized to the transmit hardware, since the time to transmit is much smaller than ¼ of a compute cycle. Ignoring the small anomaly at the beginning, this system is characterized by the formula:
(Tcompute + Ttx + Twait) × num_x_lines / num_cpus
This formula states that using four threads on four CPUs will be approximately 4 times faster than the single-threaded model we started out with.
By combining what we learned from simply having a multithreaded single-processor version, we would ideally like to have more threads than CPUs, so that the extra threads can “soak up” the idle CPU time from the transmit acknowledge waits (and the transmit slot contention waits) that naturally occur. In that case, we'd have something like this:
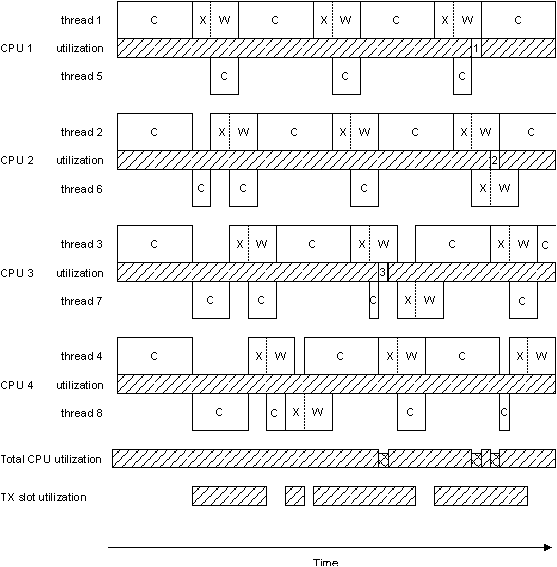
Eight threads, four CPUs.
This figure assumes a few things:
Notice from the diagram that even though we now have twice as many threads as CPUs, we still run into places where the CPUs are under-utilized. In the diagram, there are three such places where the CPU is “stalled”; these are indicated by numbers in the individual CPU utilization bar graphs:
This example also serves as an important lesson — you can't just keep adding CPUs in the hopes that things will keep getting faster. There are limiting factors. In some cases, these limiting factors are simply governed by the design of the multi-CPU motherboard — how much memory and device contention occurs when many CPUs try to access the same area of memory. In our case, notice that the “TX Slot Utilization” bar graph was starting to become full. If we added enough CPUs, they would eventually run into problems because their threads would be stalled, waiting to transmit.
In any event, by using “soaker” threads to “soak up” spare CPU, we now have much better CPU utilization. This utilization approaches:
(Tcompute + Ttx) × num_x_lines / num_cpus
In the computation per se, we're limited only by the amount of CPU we have; we're not idling any processor waiting for acknowledgment. (Obviously, that's the ideal case. As you saw in the diagram there are a few times when we're idling one CPU periodically. Also, as noted above,
Tcompute + Ttx × num_x_lines
is our limit on how fast we can go.)
While in general you can simply “ignore” whether or not you're running on an SMP architecture or a single processor, there are certain things that will bite you. Unfortunately, they may be such low-probability events that they won't show up during development but rather during testing, demos, or the worst: out in the field. Taking a few moments now to program defensively will save problems down the road.
Here are the kinds of things that you're going to run up against on an SMP system:
As discussed above in the “Where a thread is a good idea” section, threads also find use where a number of independent processing algorithms are occurring with shared data structures. While strictly speaking you could have a number of processes (each with one thread) explicitly sharing data, in some cases it's far more convenient to have a number of threads in one process instead. Let's see why and where you'd use threads in this case.
For our examples, we'll evolve a standard input/process/output model. In the most generic sense, one part of the model is responsible for getting input from somewhere, another part is responsible for processing the input to produce some form of output (or control), and the third part is responsible for feeding the output somewhere.
Let's first understand the situation from a multiple process, one-thread-per-process outlook. In this case, we'd have three processes, literally an input process, a “processing” process, and an output process:
System 1: Multiple operations, multiple processes.
This is the most highly abstracted form, and also the most “loosely coupled.” The “input” process has no real “binding” with either of the “processing” or “output” processes — it's simply responsible for gathering input and somehow giving it to the next stage (the “processing” stage). We could say the same thing of the “processing” and “output” processes — they too have no real binding with each other. We are also assuming in this example that the communication path (i.e., the input-to-processing and the processing-to-output data flow) is accomplished over some connectioned protocol (e.g., pipes, POSIX message queues, native Neutrino message passing — whatever).
Depending on the volume of data flow, we may want to optimize the communication path. The easiest way of doing this is to make the coupling between the three processes tighter. Instead of using a general-purpose connectioned protocol, we now choose a shared memory scheme (in the diagram, the thick lines indicate data flow; the thin lines, control flow):
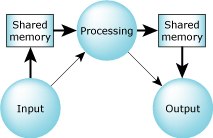
System 2: Multiple operations, shared memory between processes.
In this scheme, we've tightened up the coupling, resulting in faster and more efficient data flow. We may still use a “general-purpose” connectioned protocol to transfer “control” information around — we're not expecting the control information to consume a lot of bandwidth.
The most tightly-coupled system is represented by the following scheme:
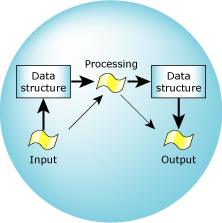
System 3: Multiple operations, multiple threads.
Here we see one process with three threads. The three threads share the data areas implicitly. Also, the control information may be implemented as it was in the previous examples, or it may also be implemented via some of the thread synchronization primitives (we've seen mutexes, barriers, and semaphores; we'll see others in a short while).
Now, let's compare the three methods using various categories, and we'll also describe some of the trade-offs.
With system 1, we see the loosest coupling. This has the advantage that each of the three processes can be easily (i.e., via the command line, as opposed to recompile/redesign) replaced with a different module. This follows naturally, because the “unit of modularity” is the entire module itself. System 1 is also the only one that can be distributed among multiple nodes in a Neutrino network. Since the communications pathway is abstracted over some connectioned protocol, it's easy to see that the three processes can be executing on any machine in the network. This may be a very powerful scalability factor for your design — you may need your system to scale up to having hundreds of machines distributed geographically (or in other ways, e.g., for peripheral hardware capability) and communicating with each other.
Once we commit to a shared memory region, however, we lose the ability to distribute over a network. Neutrino doesn't support network-distributed shared memory objects. So in system 2, we've effectively limited ourselves to running all three processes on the same box. We haven't lost the ability to easily remove or change a component, because we still have separate processes that can be controlled from the command line. But we have added the constraint that all the removable components need to conform to the shared-memory model.
In system 3, we've lost all the above abilities. We definitely can't run different threads from one process on multiple nodes (we can run them on different processors in an SMP system, though). And we've lost our configurability aspects — now we need to have an explicit mechanism to define which “input,” “processing,” or “output” algorithm we want to use (which we can solve with shared objects, also known as DLLs.)
So why would I design my system to have multiple threads like system 3? Why not go for the maximally flexible system 1?
Well, even though system 3 is the most inflexible, it is most likely going to be the fastest. There are no thread-to-thread context switches for threads in different processes, I don't have to set up memory sharing explicitly, and I don't have to use abstracted synchronization methods like pipes, POSIX message queues, or message passing to deliver the data or control information — I can use basic kernel-level thread-synchronization primitives. Another advantage is that when the system described by the one process (with the three threads) starts, I know that everything I need has been loaded off the storage medium (i.e., I'm not going to find out later that “Oops, the processing driver is missing from the disk!”). Finally, system 3 is also most likely going to be the smallest, because we won't have three individual copies of “process” information (e.g., file descriptors).
To sum up: know what the trade-offs are, and use what works for your design.
We've already seen:
Let's now finish up our discussion of synchronization by talking about:
Readers and writer locks are used for exactly what their name implies: multiple readers can be using a resource, with no writers, or one writer can be using a resource with no other writers or readers.
This situation occurs often enough to warrant a special kind of synchronization primitive devoted exclusively to that purpose.
Often you'll have a data structure that's shared by a bunch of threads. Obviously, only one thread can be writing to the data structure at a time. If more than one thread was writing, then the threads could potentially overwrite each other's data. To prevent this from happening, the writing thread would obtain the “rwlock” (the readers/writer lock) in an exclusive manner, meaning that it and only it has access to the data structure. Note that the exclusivity of the access is controlled strictly by voluntary means. It's up to you, the system designer, to ensure that all threads that touch the data area synchronize by using the rwlocks.
The opposite occurs with readers. Since reading a data area is a non-destructive operation, any number of threads can be reading the data (even if it's the same piece of data that another thread is reading). An implicit point here is that no threads can be writing to the data area while any thread or threads are reading from it. Otherwise, the reading threads may be confused by reading a part of the data, getting preempted by a writing thread, and then, when the reading thread resumes, continue reading data, but from a newer “update” of the data. A data inconsistency would then result.
Let's look at the calls that you'd use with rwlocks.
The first two calls are used to initialize the library's internal storage areas for the rwlocks:
int
pthread_rwlock_init (pthread_rwlock_t *lock,
const pthread_rwlockattr_t *attr);
int
pthread_rwlock_destroy (pthread_rwlock_t *lock);
The pthread_rwlock_init() function takes the lock argument (of type pthread_rwlock_t) and initializes it based on the attributes specified by attr. We're just going to use an attribute of NULL in our examples, which means, “Use the defaults.” For detailed information about the attributes, see the library reference pages for pthread_rwlockattr_init(), pthread_rwlockattr_destroy(), pthread_rwlockattr_getpshared(), and pthread_rwlockattr_setpshared().
When done with the rwlock, you'd typically call pthread_rwlock_destroy() to destroy the lock, which invalidates it. You should never use a lock that is either destroyed or hasn't been initialized yet.
Next we need to fetch a lock of the appropriate type. As mentioned above, there are basically two modes of locks: a reader will want “non-exclusive” access, and a writer will want “exclusive” access. To keep the names simple, the functions are named after the user of the locks:
int pthread_rwlock_rdlock (pthread_rwlock_t *lock); int pthread_rwlock_tryrdlock (pthread_rwlock_t *lock); int pthread_rwlock_wrlock (pthread_rwlock_t *lock); int pthread_rwlock_trywrlock (pthread_rwlock_t *lock);
There are four functions instead of the two that you may have expected. The “expected” functions are pthread_rwlock_rdlock() and pthread_rwlock_wrlock(), which are used by readers and writers, respectively. These are blocking calls — if the lock isn't available for the selected operation, the thread will block. When the lock becomes available in the appropriate mode, the thread will unblock. Because the thread unblocked from the call, it can now assume that it's safe to access the resource protected by the lock.
Sometimes, though, a thread won't want to block, but instead will want to see if it could get the lock. That's what the “try” versions are for. It's important to note that the “try” versions will obtain the lock if they can, but if they can't, then they won't block, but instead will just return an error indication. The reason they have to obtain the lock if they can is simple. Suppose that a thread wanted to obtain the lock for reading, but didn't want to wait in case it wasn't available. The thread calls pthread_rwlock_tryrdlock(), and is told that it could have the lock. If the pthread_rwlock_tryrdlock() didn't allocate the lock, then bad things could happen — another thread could preempt the one that was told to go ahead, and the second thread could lock the resource in an incompatible manner. Since the first thread wasn't actually given the lock, when the first thread goes to actually acquire the lock (because it was told it could), it would use pthread_rwlock_rdlock(), and now it would block, because the resource was no longer available in that mode. So, if we didn't lock it if we could, the thread that called the “try” version could still potentially block anyway!
Finally, regardless of the way that the lock was used, we need some way of releasing the lock:
int pthread_rwlock_unlock (pthread_rwlock_t *lock);
Once a thread has done whatever operation it wanted to do on the resource, it would release the lock by calling pthread_rwlock_unlock(). If the lock is now available in a mode that corresponds to the mode requested by another waiting thread, then that thread would be made READY.
Note that we can't implement this form of synchronization with just a mutex. The mutex acts as a single-threading agent, which would be okay for the writing case (where you want only one thread to be using the resource at a time) but would fall flat in the reading case, because only one reader would be allowed. A semaphore couldn't be used either, because there's no way to distinguish the two modes of access — a semaphore would allow multiple readers, but if a writer were to acquire the semaphore, as far as the semaphore is concerned this would be no different from a reader acquiring it, and now you'd have the ugly situation of multiple readers and one or more writers!
Another common situation that occurs in multithreaded programs is the need for a thread to wait until “something happens.” This “something” could be anything! It could be the fact that data is now available from a device, or that a conveyor belt has now moved to the proper position, or that data has been committed to disk, or whatever. Another twist to throw in here is that several threads may need to wait for the given event.
To accomplish this, we'd use either a condition variable (which we'll see next) or the much simpler “sleepon” lock.
To use sleepon locks, you actually need to perform several operations. Let's look at the calls first, and then look at how you'd use the locks.
int pthread_sleepon_lock (void); int pthread_sleepon_unlock (void); int pthread_sleepon_broadcast (void *addr); int pthread_sleepon_signal (void *addr); int pthread_sleepon_wait (void *addr);
|
Don't be tricked by the prefix pthread_ into thinking that these are POSIX functions — they're not. |
As described above, a thread needs to wait for something to happen. The most obvious choice in the list of functions above is the pthread_sleepon_wait(). But first, the thread needs to check if it really does have to wait. Let's set up an example. One thread is a producer thread that's getting data from some piece of hardware. The other thread is a consumer thread that's doing some form of processing on the data that just arrived. Let's look at the consumer first:
volatile int data_ready = 0;
consumer ()
{
while (1) {
while (!data_ready) {
// WAIT
}
// process data
}
}
The consumer is sitting in its main processing loop (the while (1)); it's going to do its job forever. The first thing it does is look at the data_ready flag. If this flag is a 0, it means there's no data ready. Therefore, the consumer should wait. Somehow, the producer will wake it up, at which point the consumer should reexamine its data_ready flag. Let's say that's exactly what happens, and the consumer looks at the flag and decides that it's a 1, meaning data is now available. The consumer goes off and processes the data, and then goes to see if there's more work to do, and so on.
We're going to run into a problem here. How does the consumer reset the data_ready flag in a synchronized manner with the producer? Obviously, we're going to need some form of exclusive access to the flag so that only one of those threads is modifying it at a given time. The method that's used in this case is built with a mutex, but it's a mutex that's buried in the implementation of the sleepon library, so we can access it only via two functions: pthread_sleepon_lock() and pthread_sleepon_unlock(). Let's modify our consumer:
consumer ()
{
while (1) {
pthread_sleepon_lock ();
while (!data_ready) {
// WAIT
}
// process data
data_ready = 0;
pthread_sleepon_unlock ();
}
}
Now we've added the lock and unlock around the operation of the consumer. This means that the consumer can now reliably test the data_ready flag, with no race conditions, and also reliably set the flag.
Okay, great. Now what about the “WAIT” call? As we suggested earlier, it's effectively the pthread_sleepon_wait() call. Here's the second while loop:
while (!data_ready) {
pthread_sleepon_wait (&data_ready);
}
The pthread_sleepon_wait() actually does three distinct steps!
The reason it has to unlock and lock the sleepon library's mutex is simple — since the whole idea of the mutex is to ensure mutual exclusion to the data_ready variable, this means that we want to lock out the producer from touching the data_ready variable while we're testing it. But, if we don't do the unlock part of the operation, the producer would never be able to set it to tell us that data is indeed available! The re-lock operation is done purely as a convenience; this way the user of the pthread_sleepon_wait() doesn't have to worry about the state of the lock when it wakes up.
Let's switch over to the producer side and see how it uses the sleepon library. Here's the full implementation:
producer ()
{
while (1) {
// wait for interrupt from hardware here...
pthread_sleepon_lock ();
data_ready = 1;
pthread_sleepon_signal (&data_ready);
pthread_sleepon_unlock ();
}
}
As you can see, the producer locks the mutex as well so that it can have exclusive access to the data_ready variable in order to set it.
|
It's not the act of writing a 1 to data_ready that awakens the client! It's the call to pthread_sleepon_signal() that does it. |
Let's examine in detail what happens. We've identified the consumer and producer states as:
| State | Meaning |
|---|---|
| CONDVAR | Waiting for the underlying condition variable associated with the sleepon |
| MUTEX | Waiting for a mutex |
| READY | Capable of using, or already using, the CPU |
| INTERRUPT | Waiting for an interrupt from the hardware |
| Action | Mutex owner | Consumer state | Producer state |
|---|---|---|---|
| Consumer locks mutex | Consumer | READY | INTERRUPT |
| Consumer examines data_ready | Consumer | READY | INTERRUPT |
| Consumer calls pthread_sleepon_wait() | Consumer | READY | INTERRUPT |
| pthread_sleepon_wait() unlocks mutex | Free | READY | INTERRUPT |
| pthread_sleepon_wait() blocks | Free | CONDVAR | INTERRUPT |
| Time passes | Free | CONDVAR | INTERRUPT |
| Hardware generates data | Free | CONDVAR | READY |
| Producer locks mutex | Producer | CONDVAR | READY |
| Producer sets data_ready | Producer | CONDVAR | READY |
| Producer calls pthread_sleepon_signal() | Producer | CONDVAR | READY |
| Consumer wakes up, pthread_sleepon_wait() tries to lock mutex | Producer | MUTEX | READY |
| Producer releases mutex | Free | MUTEX | READY |
| Consumer gets mutex | Consumer | READY | READY |
| Consumer processes data | Consumer | READY | READY |
| Producer waits for more data | Consumer | READY | INTERRUPT |
| Time passes (consumer processing) | Consumer | READY | INTERRUPT |
| Consumer finishes processing, unlocks mutex | Free | READY | INTERRUPT |
| Consumer loops back to top, locks mutex | Consumer | READY | INTERRUPT |
The last entry in the table is a repeat of the first entry — we've gone around one complete cycle.
What's the purpose of the data_ready variable? It actually serves two purposes:
We'll defer the discussion of “What's the difference between pthread_sleepon_signal() and pthread_sleepon_broadcast() ” to the discussion of condition variables next.
Condition variables (or “condvars”) are remarkably similar to the sleepon locks we just saw above. In fact, sleepon locks are built on top of condvars, which is why we had a state of CONDVAR in the explanation table for the sleepon example. It bears repeating that the pthread_cond_wait() function releases the mutex, waits, and then reacquires the mutex, just like the pthread_sleepon_wait() function did.
Let's skip the preliminaries and redo the example of the producer and consumer from the sleepon section, using condvars instead. Then we'll discuss the calls.
/*
* cp1.c
*/
#include <stdio.h>
#include <pthread.h>
int data_ready = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t condvar = PTHREAD_COND_INITIALIZER;
void *
consumer (void *notused)
{
printf ("In consumer thread...\n");
while (1) {
pthread_mutex_lock (&mutex);
while (!data_ready) {
pthread_cond_wait (&condvar, &mutex);
}
// process data
printf ("consumer: got data from producer\n");
data_ready = 0;
pthread_cond_signal (&condvar);
pthread_mutex_unlock (&mutex);
}
}
void *
producer (void *notused)
{
printf ("In producer thread...\n");
while (1) {
// get data from hardware
// we'll simulate this with a sleep (1)
sleep (1);
printf ("producer: got data from h/w\n");
pthread_mutex_lock (&mutex);
while (data_ready) {
pthread_cond_wait (&condvar, &mutex);
}
data_ready = 1;
pthread_cond_signal (&condvar);
pthread_mutex_unlock (&mutex);
}
}
main ()
{
printf ("Starting consumer/producer example...\n");
// create the producer and consumer threads
pthread_create (NULL, NULL, producer, NULL);
pthread_create (NULL, NULL, consumer, NULL);
// let the threads run for a bit
sleep (20);
}
Pretty much identical to the sleepon example we just saw, with a few variations (we also added some printf() functions and a main() so that the program would run!). Right away, the first thing that we see is a new data type: pthread_cond_t. This is simply the declaration of the condition variable; we've called ours condvar.
Next thing we notice is that the structure of the consumer is identical to that of the consumer in the previous sleepon example. We've replaced the pthread_sleepon_lock() and pthread_sleepon_unlock() with the standard mutex versions (pthread_mutex_lock() and pthread_mutex_unlock()). The pthread_sleepon_wait() was replaced with pthread_cond_wait(). The main difference is that the sleepon library has a mutex buried deep within it, whereas when we use condvars, we explicitly pass the mutex. We get a lot more flexibility this way.
Finally, we notice that we've got pthread_cond_signal() instead of pthread_sleepon_signal() (again with the mutex passed explicitly).
In the sleepon section, we promised to talk about the difference between the pthread_sleepon_signal() and pthread_sleepon_broadcast() functions. In the same breath, we'll talk about the difference between the two condvar functions pthread_cond_signal() and pthread_cond_broadcast().
The short story is this: the “signal” version will wake up only one thread. So, if there were multiple threads blocked in the “wait” function, and a thread did the “signal,” then only one of the threads would wake up. Which one? The highest priority one. If there are two or more at the same priority, the ordering of wakeup is indeterminate. With the “broadcast” version, all blocked threads will wake up.
It may seem wasteful to wake up all threads. On the other hand, it may seem sloppy to wake up only one (effectively random) thread.
Therefore, we should look at where it makes sense to use one over the other. Obviously, if you have only one thread waiting, as we did in either version of the consumer program, a “signal” will do just fine — one thread will wake up and, guess what, it'll be the only thread that's currently waiting.
In a multithreaded situation, we've got to ask: “Why are these threads waiting?” There are usually two possible answers:
Or:
In the first case, we can imagine that all the threads have code that might look like the following:
/*
* cv1.c
*/
#include <stdio.h>
#include <pthread.h>
pthread_mutex_t mutex_data = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cv_data = PTHREAD_COND_INITIALIZER;
int data;
thread1 ()
{
for (;;) {
pthread_mutex_lock (&mutex_data);
while (data == 0) {
pthread_cond_wait (&cv_data, &mutex_data);
}
// do something
pthread_mutex_unlock (&mutex_data);
}
}
// thread2, thread3, etc have the identical code.
In this case, it really doesn't matter which thread gets the data, provided that one of them gets it and does something with it.
However, if you have something like this, things are a little different:
/*
* cv2.c
*/
#include <stdio.h>
#include <pthread.h>
pthread_mutex_t mutex_xy = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cv_xy = PTHREAD_COND_INITIALIZER;
int x, y;
int isprime (int);
thread1 ()
{
for (;;) {
pthread_mutex_lock (&mutex_xy);
while ((x > 7) && (y != 15)) {
pthread_cond_wait (&cv_xy, &mutex_xy);
}
// do something
pthread_mutex_unlock (&mutex_xy);
}
}
thread2 ()
{
for (;;) {
pthread_mutex_lock (&mutex_xy);
while (!isprime (x)) {
pthread_cond_wait (&cv_xy, &mutex_xy);
}
// do something
pthread_mutex_unlock (&mutex_xy);
}
}
thread3 ()
{
for (;;) {
pthread_mutex_lock (&mutex_xy);
while (x != y) {
pthread_cond_wait (&cv_xy, &mutex_xy);
}
// do something
pthread_mutex_unlock (&mutex_xy);
}
}
In these cases, waking up one thread isn't going to cut it! We must wake up all three threads and have each of them check to see if its predicate has been satisfied or not.
This nicely reflects the second case in our question above (“Why are these threads waiting?”). Since the threads are all waiting on different conditions (thread1() is waiting for x to be less than or equal to 7 or y to be 15, thread2() is waiting for x to be a prime number, and thread3() is waiting for x to be equal to y), we have no choice but to wake them all.
Sleepons have one principal advantage over condvars. Suppose that you want to synchronize many objects. With condvars, you'd typically associate one condvar per object. Therefore, if you had M objects, you'd most likely have M condvars. With sleepons, the underlying condvars (on top of which sleepons are implemented) are allocated dynamically as threads wait for a particular object. Therefore, using sleepons with M objects and N threads blocked, you'd have (at most) N condvars (instead of M).
However, condvars are more flexible than sleepons, because:
The first point might just be viewed as being argumentative. :-) The second point, however, is significant. When the mutex is buried in the library, this means that there can be only one per process — regardless of the number of threads in that process, or the number of different “sets” of data variables. This can be a very limiting factor, especially when you consider that you must use the one and only mutex to access any and all data variables that any thread in the process needs to touch!
A much better design is to use multiple mutexes, one for each data set, and explicitly combine them with condition variables as required. The true power and danger of this approach is that there is absolutely no compile time or run time checking to make sure that you:
The easiest way around these problems is to have a good design and design review, and also to borrow techniques from object-oriented programming (like having the mutex contained in a data structure, having routines to access the data structure, etc.). Of course, how much of one or both you apply depends not only on your personal style, but also on performance requirements.
The key points to remember when using condvars are:
Here's a picture:
One-to-one mutex and condvar associations.
One interesting note. Since there is no checking, you can do things like associate one set of variables with mutex “ABC,” and another set of variables with mutex “DEF,” while associating both sets of variables with condvar “ABCDEF:”
Many-to-one mutex and condvar associations.
This is actually quite useful. Since the mutex is always to be used for “access and testing,” this implies that I have to choose the correct mutex whenever I want to look at a particular variable. Fair enough — if I'm examining variable “C,” I obviously need to lock mutex “MutexABC.” What if I changed variable “E”? Well, before I change it, I had to acquire the mutex “MutexDEF.” Then I changed it, and hit condvar “CondvarABCDEF” to tell others about the change. Shortly thereafter, I would release the mutex.
Now, consider what happens. Suddenly, I have a bunch of threads that had been waiting on “CondvarABCDEF” that now wake up (from their pthread_cond_wait()). The waiting function immediately attempts to reacquire the mutex. The critical point here is that there are two mutexes to acquire. This means that on an SMP system, two concurrent streams of threads can run, each examining what it considers to be independent variables, using independent mutexes. Cool, eh?
Neutrino lets you do something else that's elegant. POSIX says that a mutex must operate between threads in the same process, and lets a conforming implementation extend that. Neutrino extends this by allowing a mutex to operate between threads in different processes. To understand why this works, recall that there really are two parts to what's viewed as the “operating system” — the kernel, which deals with scheduling, and the process manager, which worries about memory protection and “processes” (among other things). A mutex is really just a synchronization object used between threads. Since the kernel worries only about threads, it really doesn't care that the threads are operating in different processes — this is an issue for the process manager.
So, if you've set up a shared memory area between two processes, and you've initialized a mutex in that shared memory, there's nothing stopping you from synchronizing multiple threads in those two (or more!) processes via the mutex. The same pthread_mutex_lock() and pthread_mutex_unlock() functions will still work.
Another thing that Neutrino has added is the concept of thread pools. You'll often notice in your programs that you want to be able to run a certain number of threads, but you also want to be able to control the behavior of those threads within certain limits. For example, in a server you may decide that initially just one thread should be blocked, waiting for a message from a client. When that thread gets a message and is off servicing a request, you may decide that it would be a good idea to create another thread, so that it could be blocked waiting in case another request arrived. This second thread would then be available to handle that request. And so on. After a while, when the requests had been serviced, you would now have a large number of threads sitting around, waiting for further requests. In order to conserve resources, you may decide to kill off some of those “extra” threads.
This is in fact a common operation, and Neutrino provides a library to help with this. We'll see the thread pool functions again in the Resource Managers chapter.
It's important for the discussions that follow to realize there are really two distinct operations that threads (that are used in thread pools) perform:
The blocking operation doesn't generally consume CPU. In a typical server, this is where the thread is waiting for a message to arrive. Contrast that with the processing operation, where the thread may or may not be consuming CPU (depending on how the process is structured). In the thread pool functions that we'll look at later, you'll see that we have the ability to control the number of threads in the blocking operation as well as the number of threads that are in the processing operations.
Neutrino provides the following functions to deal with thread pools:
#include <sys/dispatch.h>
thread_pool_t *
thread_pool_create (thread_pool_attr_t *attr,
unsigned flags);
int
thread_pool_destroy (thread_pool_t *pool);
int
thread_pool_start (void *pool);
int
thread_pool_limits (thread_pool_t *pool,
int lowater,
int hiwater,
int maximum,
int increment,
unsigned flags);
int
thread_pool_control (thread_pool_t *pool,
thread_pool_attr_t *attr,
uint16_t lower,
uint16_t upper,
unsigned flags);
As you can see from the functions provided, you first create a thread pool definition using thread_pool_create(), and then start the thread pool via thread_pool_start(). When you're done with the thread pool, you can use thread_pool_destroy() to clean up after yourself. Note that you might never call thread_pool_destroy(), as in the case where the program is a server that runs “forever.” The thread_pool_limits() function is used to specify thread pool behavior and adjust attributes of the thread pool, and the thread_pool_control() function is a convenience wrapper for the thread_pool_limits() function.
So, the first function to look at is thread_pool_create(). It takes two parameters, attr and flags. The attr is an attributes structure that defines the operating characteristics of the thread pool (from <sys/dispatch.h>):
typedef struct _thread_pool_attr {
// thread pool functions and handle
THREAD_POOL_HANDLE_T *handle;
THREAD_POOL_PARAM_T
*(*block_func)(THREAD_POOL_PARAM_T *ctp);
void
(*unblock_func)(THREAD_POOL_PARAM_T *ctp);
int
(*handler_func)(THREAD_POOL_PARAM_T *ctp);
THREAD_POOL_PARAM_T
*(*context_alloc)(THREAD_POOL_HANDLE_T *handle);
void
(*context_free)(THREAD_POOL_PARAM_T *ctp);
// thread pool parameters
pthread_attr_t *attr;
unsigned short lo_water;
unsigned short increment;
unsigned short hi_water;
unsigned short maximum;
} thread_pool_attr_t;
I've broken the thread_pool_attr_t type into two sections, one that contains the functions and handle for the threads in the thread pool, and another that contains the operating parameters for the thread pool.
Let's first look at the “thread pool parameters” to see how you control the number and attributes of threads that will be operating in this thread pool. Keep in mind that we'll be talking about the “blocking operation” and the “processing operation” (when we look at the callout functions, we'll see how these relate to each other).
The following diagram illustrates the relationship of the lo_water, hi_water, and maximum parameters:
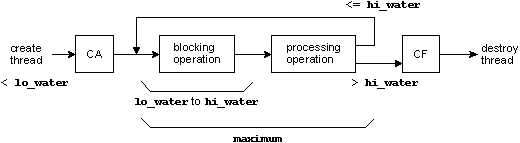
Thread flow when using thread pools.
(Note that “CA” is the context_alloc() function, “CF” is the context_free() function, “blocking operation” is the block_func() function, and “processing operation” is the handler_func().)
One other key parameter to controlling the threads is the flags parameter passed to the thread_pool_create() function. It can have one of the following values:
The above descriptions may seem a little dry. Let's look at an example.
You can find the complete version of tp1.c in the Sample Programs appendix. Here, we'll just focus on the lo_water, hi_water, increment, and the maximum members of the thread pool control structure:
/*
* part of tp1.c
*/
#include <sys/dispatch.h>
int
main ()
{
thread_pool_attr_t tp_attr;
void *tpp;
…
tp_attr.lo_water = 3;
tp_attr.increment = 2;
tp_attr.hi_water = 7;
tp_attr.maximum = 10;
…
tpp = thread_pool_create (&tp_attr, POOL_FLAG_USE_SELF);
if (tpp == NULL) {
fprintf (stderr,
"%s: can't thread_pool_create, errno %s\n",
progname, strerror (errno));
exit (EXIT_FAILURE);
}
thread_pool_start (tpp);
…
After setting the members, we call thread_pool_create() to create a thread pool. This returns a pointer to a thread pool control structure (tpp), which we check against NULL (which would indicate an error). Finally we call thread_pool_start() with the tpp thread pool control structure.
I've specified POOL_FLAG_USE_SELF which means that the thread that called thread_pool_start() will be considered an available thread for the thread pool. So, at this point, there is only that one thread in the thread pool library. Since we have a lo_water value of 3, the library immediately creates increment number of threads (2 in this case). At this point, 3 threads are in the library, and all 3 of them are in the blocking operation. The lo_water condition is satisfied, because there are at least that number of threads in the blocking operation; the hi_water condition is satisfied, because there are less than that number of threads in the blocking operation; and finally, the maximum condition is satisfied as well, because we don't have more than that number of threads in the thread pool library.
Now, one of the threads in the blocking operation unblocks (e.g., in a server application, a message was received). This means that now one of the three threads is no longer in the blocking operation (instead, that thread is now in the processing operation). Since the count of blocking threads is less than the lo_water, it trips the lo_water trigger and causes the library to create increment (2) threads. So now there are 5 threads total (4 in the blocking operation, and 1 in the processing operation).
More threads unblock. Let's assume that none of the threads in the processing operation none completes any of their requests yet. Here's a table illustrating this, starting at the initial state (we've used “Proc Op” for the processing operation, and “Blk Op” for the blocking operation, as we did in the previous diagram, “Thread flow when using thread pools.”):
| Event | Proc Op | Blk Op | Total |
|---|---|---|---|
| Initial | 0 | 1 | 1 |
| lo_water trip | 0 | 3 | 3 |
| Unblock | 1 | 2 | 3 |
| lo_water trip | 1 | 4 | 5 |
| Unblock | 2 | 3 | 5 |
| Unblock | 3 | 2 | 5 |
| lo_water trip | 3 | 4 | 7 |
| Unblock | 4 | 3 | 7 |
| Unblock | 5 | 2 | 7 |
| lo_water trip | 5 | 4 | 9 |
| Unblock | 6 | 3 | 9 |
| Unblock | 7 | 2 | 9 |
| lo_water trip | 7 | 3 | 10 |
| Unblock | 8 | 2 | 10 |
| Unblock | 9 | 1 | 10 |
| Unblock | 10 | 0 | 10 |
As you can see, the library always checks the lo_water variable and creates increment threads at a time until it hits the limit of the maximum variable (as it did when the “Total” column reached 10 — no more threads were being created, even though the count had underflowed the lo_water).
This means that at this point, there are no more threads waiting in the blocking operation. Let's assume that the threads are now finishing their requests (from the processing operation); watch what happens with the hi_water trigger:
| Event | Proc Op | Blk Op | Total |
|---|---|---|---|
| Completion | 9 | 1 | 10 |
| Completion | 8 | 2 | 10 |
| Completion | 7 | 3 | 10 |
| Completion | 6 | 4 | 10 |
| Completion | 5 | 5 | 10 |
| Completion | 4 | 6 | 10 |
| Completion | 3 | 7 | 10 |
| Completion | 2 | 8 | 10 |
| hi_water trip | 2 | 7 | 9 |
| Completion | 1 | 8 | 9 |
| hi_water trip | 1 | 7 | 8 |
| Completion | 0 | 8 | 8 |
| hi_water trip | 0 | 7 | 7 |
Notice how nothing really happened during the completion of processing for the threads until we tripped over the hi_water trigger. The implementation is that as soon as the thread finishes, it looks at the number of receive blocked threads and decides to kill itself if there are too many (i.e., more than hi_water) waiting at that point. The nice thing about the lo_water and hi_water limits in the structures is that you can effectively have an “operating range” where a sufficient number of threads are available, and you're not unnecessarily creating and destroying threads. In our case, after the operations performed by the above tables, we now have a system that can handle up to 4 requests simultaneously without creating more threads (7 - 4 = 3, which is the lo_water trip).
Now that we have a good feel for how the number of threads is controlled, let's turn our attention to the other members of the thread pool attribute structure (from above):
// thread pool functions and handle
THREAD_POOL_HANDLE_T *handle;
THREAD_POOL_PARAM_T
*(*block_func)(THREAD_POOL_PARAM_T *ctp);
void
(*unblock_func)(THREAD_POOL_PARAM_T *ctp);
int
(*handler_func)(THREAD_POOL_PARAM_T *ctp);
THREAD_POOL_PARAM_T
*(*context_alloc)(THREAD_POOL_HANDLE_T *handle);
void
(*context_free)(THREAD_POOL_PARAM_T *ctp);
Recall from the diagram “Thread flow when using thread pools,” that the context_alloc() function gets called for every new thread being created. (Similarly, the context_free() function gets called for every thread being destroyed.)
The handle member of the structure (above) is passed to the context_alloc() function as its sole parameter. The context_alloc() function is responsible for performing any per-thread setup required and for returning a context pointer (called ctp in the parameter lists). Note that the contents of the context pointer are entirely up to you — the library doesn't care what you put into the context pointer.
Now that the context has been created by context_alloc(), the block_func() function is called to perform the blocking operation. Note that the block_func() function gets passed the results of the context_alloc() function. Once the block_func() function unblocks, it returns a context pointer, which gets passed by the library to the handler_func(). The handler_func() is responsible for performing the “work” — for example, in a typical server, this is where the message from the client is processed. The handler_func() must return a zero for now — non-zero values are reserved for future expansion by QSS. The unblock_func() is also reserved at this time; just leave it as NULL. Perhaps this pseudo code sample will clear things up (it's based on the same flow as shown in “Thread flow when using thread pools,” above):
FOREVER DO
IF (#threads < lo_water) THEN
IF (#threads_total < maximum) THEN
create new thread
context = (*context_alloc) (handle);
ENDIF
ENDIF
retval = (*block_func) (context);
(*handler_func) (retval);
IF (#threads > hi_water) THEN
(*context_free) (context)
kill thread
ENDIF
DONE
Note that the above is greatly simplified; its only purpose is to show you the data flow of the ctp and handle parameters and to give some sense of the algorithms used to control the number of threads.
So far we've talked about scheduling algorithms and thread states, but we haven't said much yet about why and when things are rescheduled. There's a common misconception that rescheduling just “occurs,” without any real causes. Actually, this is a useful abstraction during design! But it's important to understand the conditions that cause rescheduling. Recall the diagram “Scheduling roadmap” (in the “The kernel's role” section).
Rescheduling occurs only because of:
Rescheduling due to a hardware interrupt occurs in two cases:
The realtime clock generates periodic interrupts for the kernel, causing time-based rescheduling.
For example, if you issue a sleep (10); call, a number of realtime clock interrupts will occur; the kernel increments the time-of-day clock at each interrupt. When the time-of-day clock indicates that 10 seconds have elapsed, the kernel reschedules your thread as READY. (This is discussed in more detail in the Clocks, Timers, and Getting a Kick Every So Often chapter.)
Other threads might wait for hardware interrupts from peripherals, such as the serial port, a hard disk, or an audio card. In this case, they are blocked in the kernel waiting for a hardware interrupt; the thread will be rescheduled by the kernel only after that “event” is generated.
If the rescheduling is caused by a thread issuing a kernel call, the rescheduling is done immediately and can be considered asynchronous to the timer and other interrupts.
For example, above we called sleep(10);. This C library function is eventually translated into a kernel call. At that point, the kernel made a rescheduling decision to take your thread off of the READY queue for that priority, and then schedule another thread that was READY.
There are many kernel calls that cause a process to be rescheduled. Most of them are fairly obvious. Here are a few:
The final cause of rescheduling, a CPU fault, is an exception, somewhere between a hardware interrupt and a kernel call. It operates asynchronously to the kernel (like an interrupt) but operates synchronously with the user code that caused it (like a kernel call — for example, a divide-by-zero exception). The same discussion as above (for hardware interrupts and kernel calls) applies to faults.
Neutrino offers a rich set of scheduling options with threads, the primary scheduling elements. Processes are defined as a unit of resource ownership (e.g., a memory area) and contain one or more threads.
Threads can use any of the following synchronization methods:
Note that mutexes, semaphores, and condition variables can be used between threads in the same or different processes, but that sleepons can be used only between threads in the same process (because the library has a mutex “hidden” in the process's address space).
As well as synchronization, threads can be scheduled (using a priority and a scheduling algorithm), and they'll automatically run on a single-processor box or an SMP box.
Whenever we talk about creating a “process” (mainly as a means of porting code from single-threaded implementations), we're really creating an address space with one thread running in it — that thread starts at main() or at fork() or vfork() depending on the function called.
|
|
|
|